
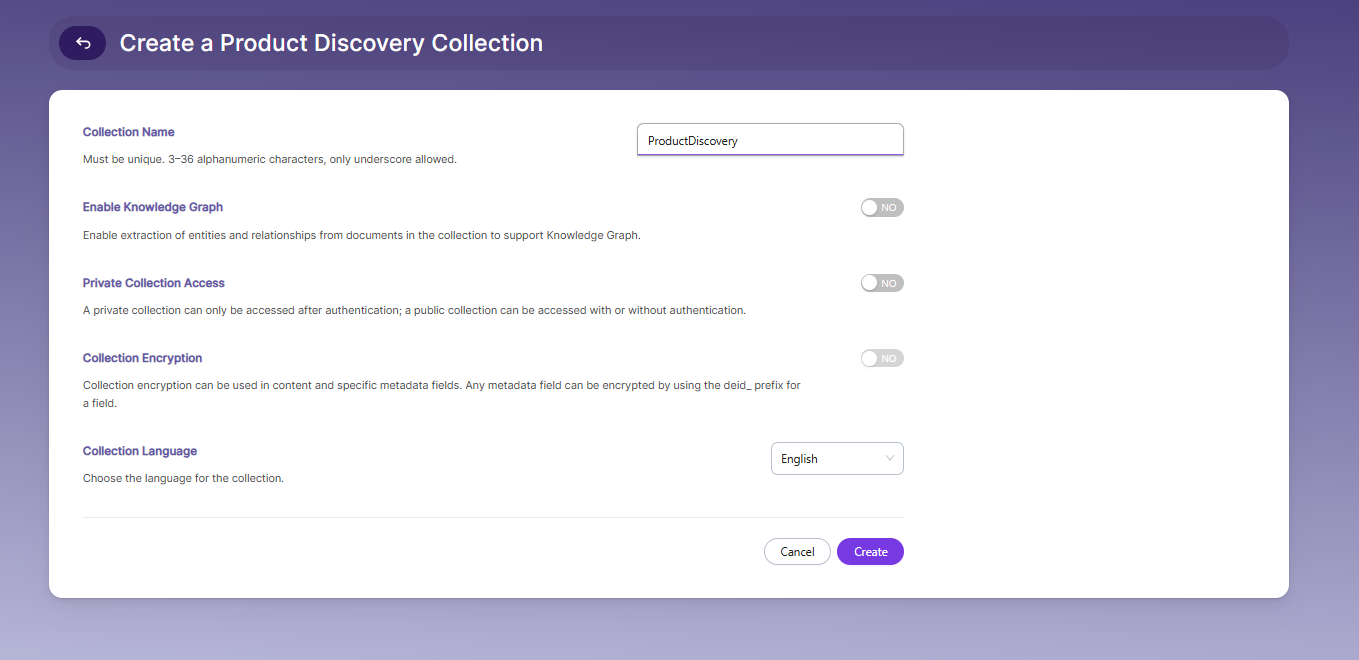
Product Discovery Collection
A Product Discovery Collection is used to index information from a product dataset. In simple terms, each product in your dataset becomes one document in the collection.
Creating Product Discovery Collection
Follow these steps to create a new Product Discovery Collection:
- Log in to the Admin Console
- Go to the Collections tab
- Click "Create a New Collection" or the "+" button
- Choose "Product Discovery Collection" as the type
- Enter a unique name for your collection (e.g., "ecommerce")
- Choose whether the collection should be Private or Public
- Set the Encryption level based on your security needs
- Select the content language (if not English)
- Click "Save" to finish creating your collection
- After you create the Product Discovery collection, you will be automatically taken to the Data Settings tab..
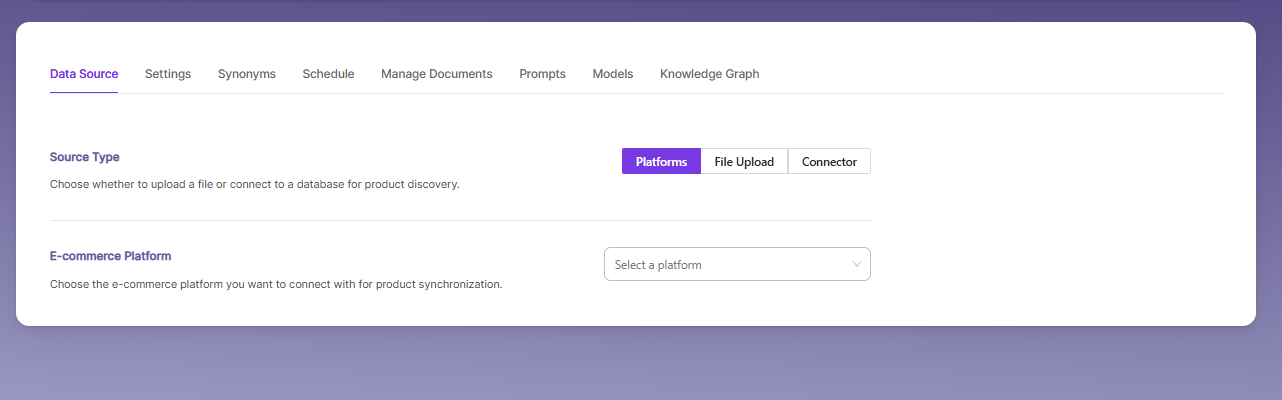
Data Settings
- In the Data Settings tab, you can import test data in three ways: Platforms a ecommerce platform selection Upload a product file or Connect to CDATA Connectors to pull records.

-
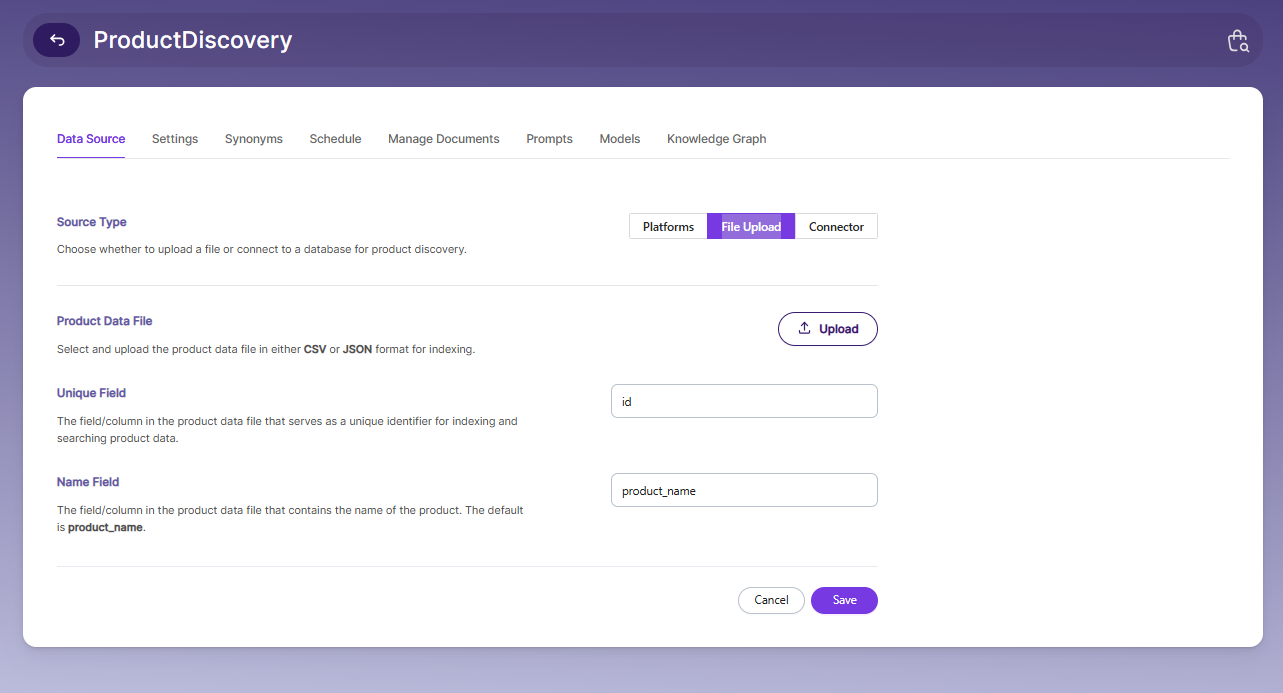
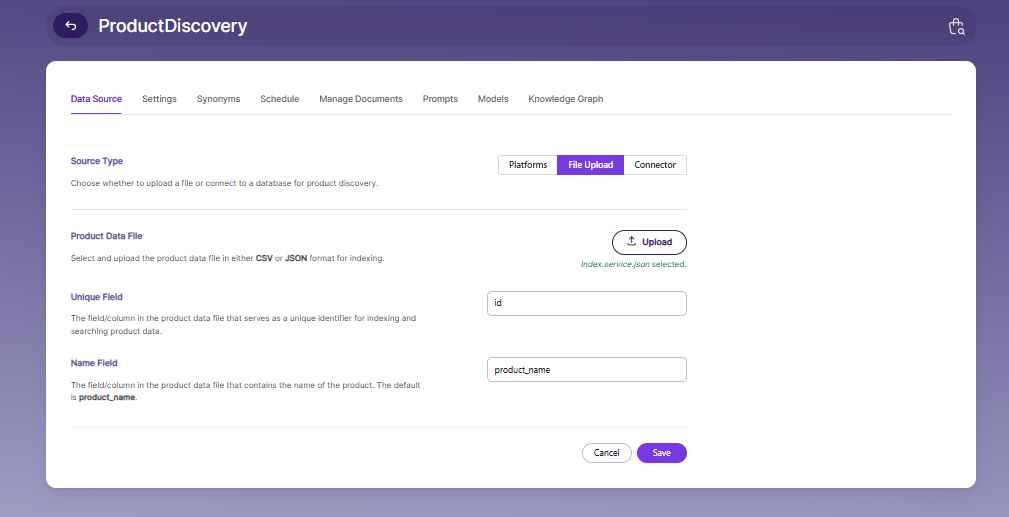
For Product Discovery Collection Data Settings, you need a product data file and a unique field inside that file.
-
To upload your product data file, click the Upload button. You can upload a CSV or JSON file.
-
-
After you upload a CSV file, the file path and other details will appear as shown in the image.
-
If you upload a JSON file, the folder path and unique field will appear after upload, as shown in the image.
-
Click Save to store your settings.
-
After saving, you can start indexing the uploaded CSV or JSON file.
-
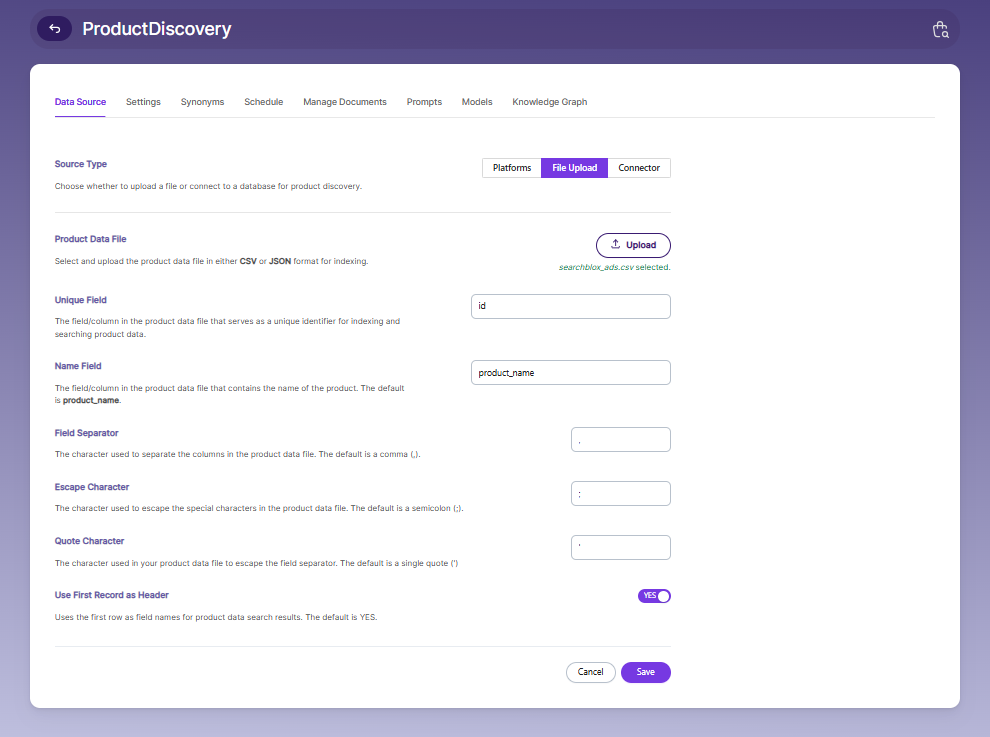
The table below shows all the settings available in the Product Discovery collection.
| Field | Description |
|---|---|
| Folder Path | The place inside the SearchBlox folder where your uploaded CSV/JSON file is stored, which can be done by uploading the file. |
| Unique Field | The CSV column or JSON attribute that has unique values in every record. This helps in indexing and searching. |
| Field Separator | The symbol used to separate values in a CSV file. (Default: ,) |
| Escape Character | The character used to handle special characters in the file. (Default: ;) |
| Quote Character | The character used to wrap text values. (Default: ’) |
| Use first record as header | Select this if the first row of the CSV file should be used as the header. |
-
If you choose Connect, select the database type, enter the database URL, and provide the query to pull records from the database.
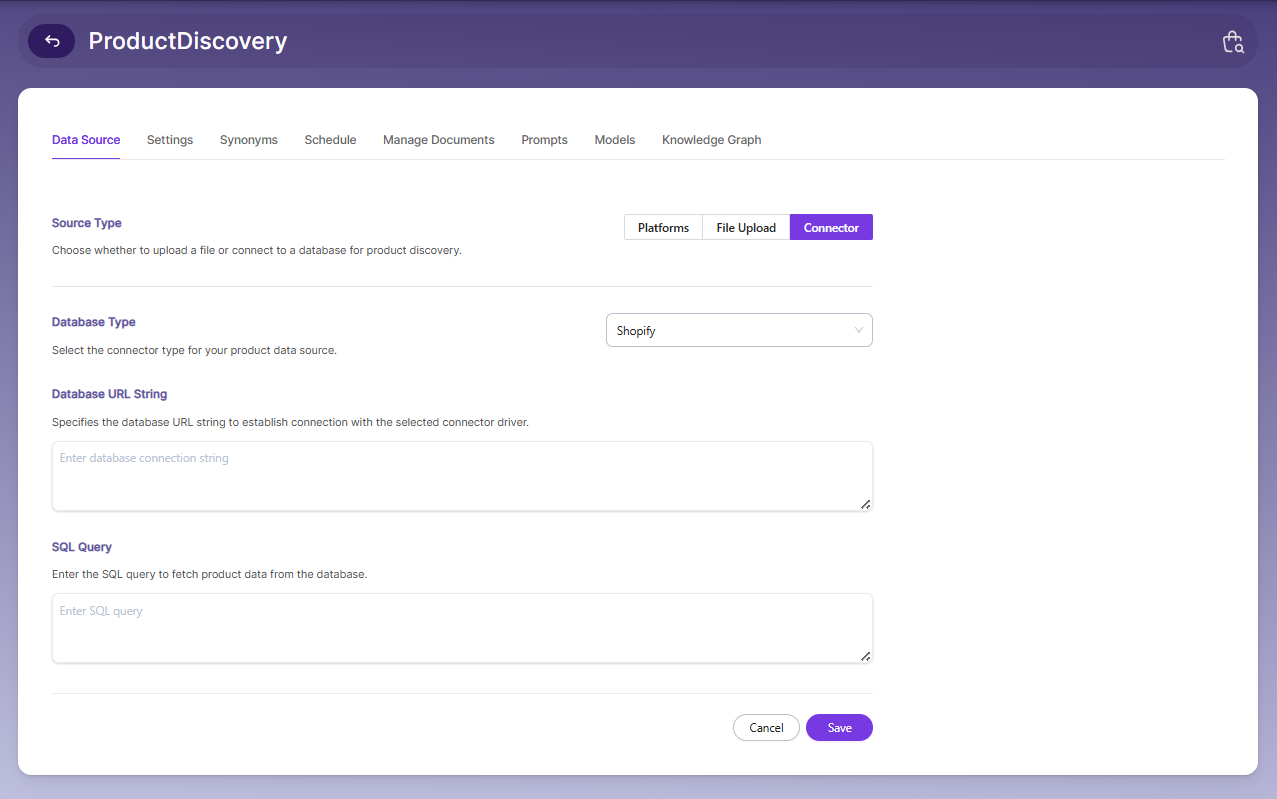
| Field | Description |
|---|---|
| Database Type | Choose the type from the drop-down list. By default it's Shopify. |
| Database URL String | CDATA Connection String. Example : jdbc:shopify:AppId=xyxcvg;Password=scab6d19db4c47769f3240d;ShopUrl=<https://xyz1-.myshopify.com>; |
| SQL Query | Query to fetch the records from database. |
Settings
Index related settings for Product discovery collection is shown in this tab.
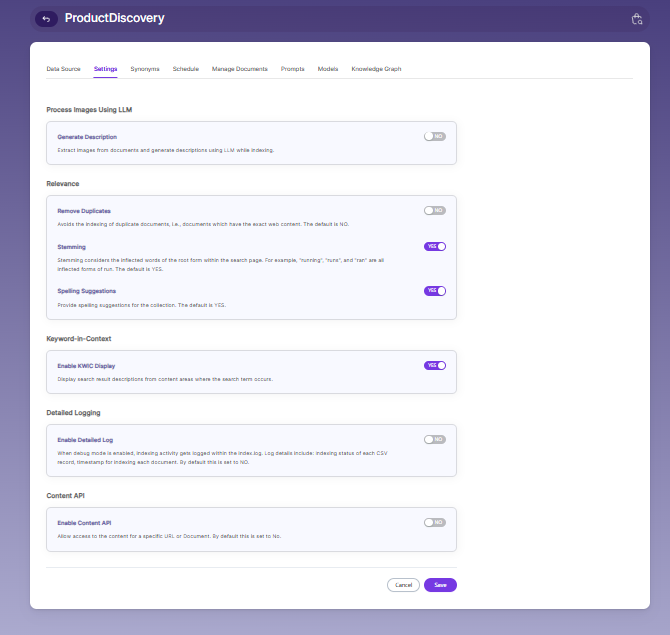
| Field | Description |
|---|---|
| Relevance - Remove Duplicate | Prevents indexing of documents that have the exact same content. Default: NO |
| Relevance - Stemming | Matches different word forms of the same root word (e.g., run, running, ran). Default: YES |
| Relevance - Spelling Suggestions | Gives spelling suggestions during search. Default: YES |
| Keyword-in-Context Display | Shows search results with snippets taken from the part of the content where the keyword appears. |
| Enable Detailed Log Settings | When debug mode is on, detailed indexing logs are saved in index.log, including status, timestamps, and indexing time. Default: NO |
| Enable Content API | Allows indexing of document content that includes special characters. |
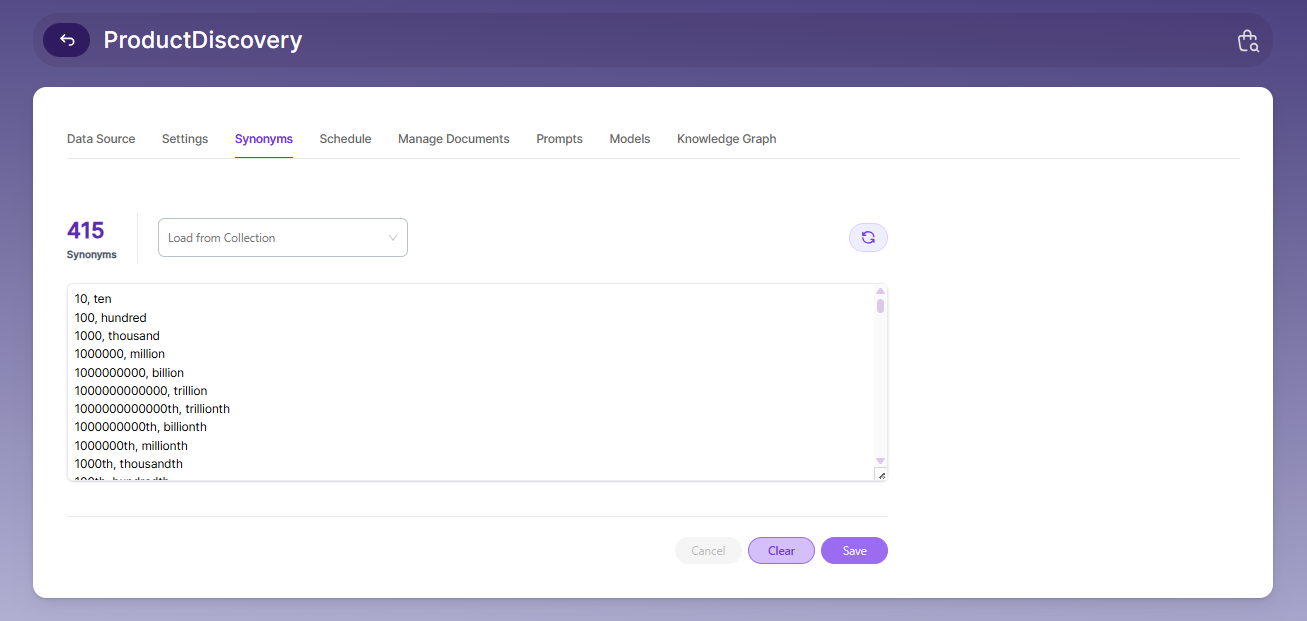
Synonyms
Synonyms help find related documents even when the exact search term isn’t used. For example, if someone searches for “global,” results containing “world” or “international” will also appear.
You can also load synonyms from your existing collections.
Schedule and Index
You can set how often indexing should run and the start date/time for indexing the collection based on the selected folder path. SearchBlox supports the following schedule frequencies:
- Once
- Hourly
- Daily
- Every 48 Hours
- Every 96 Hours
- Weekly
- Monthly
The Product Discovery collection allows you to perform the following operations.
| Enable Scheduler for Indexing | Turn this on to set when indexing should start and how often it should run. |
| Save | Saves your scheduler settings for the collection so indexing can run automatically. |
| View all Schedules | Opens the Schedules section where you can see all indexing schedules for all collections. |
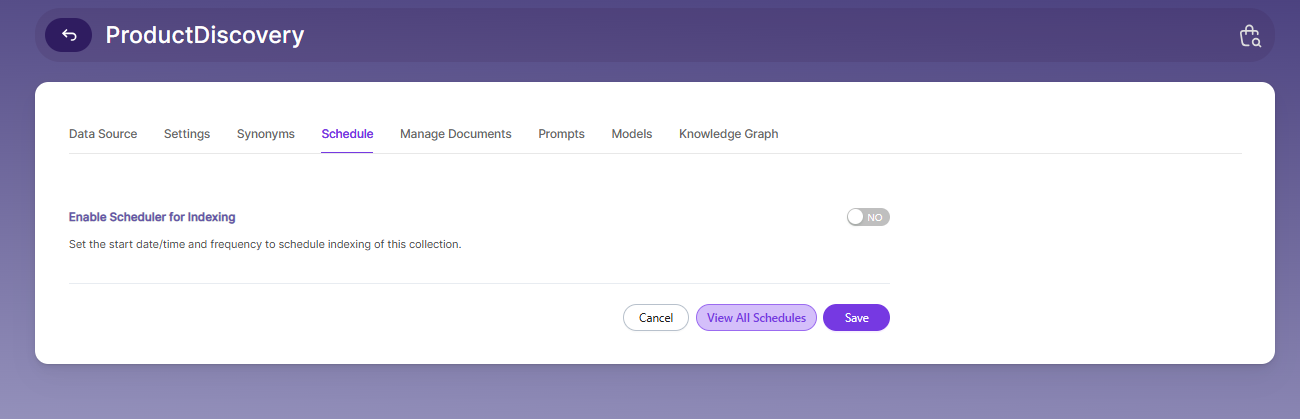
Manage Documents Tab
-
Using Manage Documents tab we can do the following operations:
- Filter
- View content
- View metadata
- Refresh
- Delete
-
To delete a file from your collection, enter the file path and click "Delete".
-
To see the status of an indexed file, click "View Metadata".
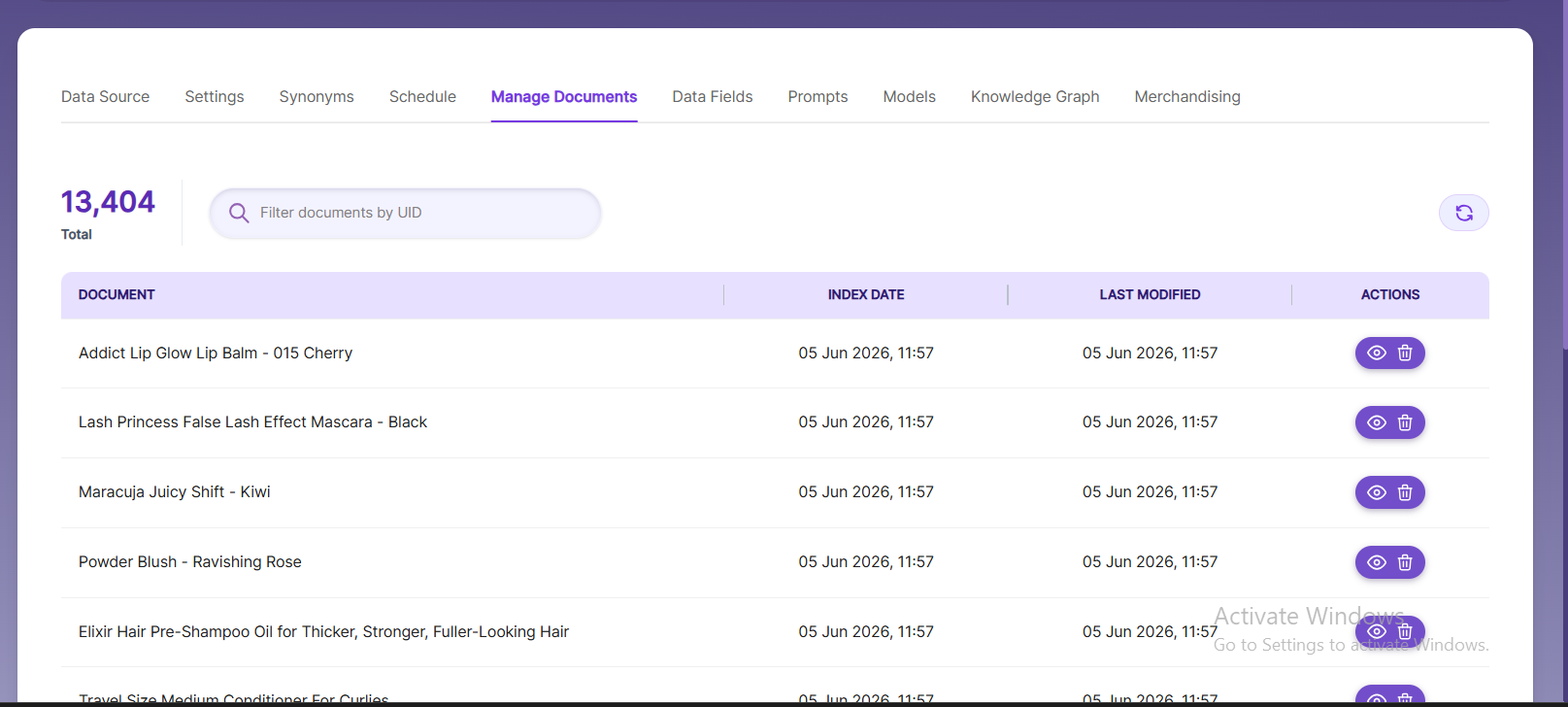
Prompts
- When LLM/RAG is enabled, you can edit AI-based prompts for Title, Description, Topic, Image Description, and Smart FAQs.
- You can customize these prompts anytime, and use Restore Default to reset them back to the original SearchBlox settings.
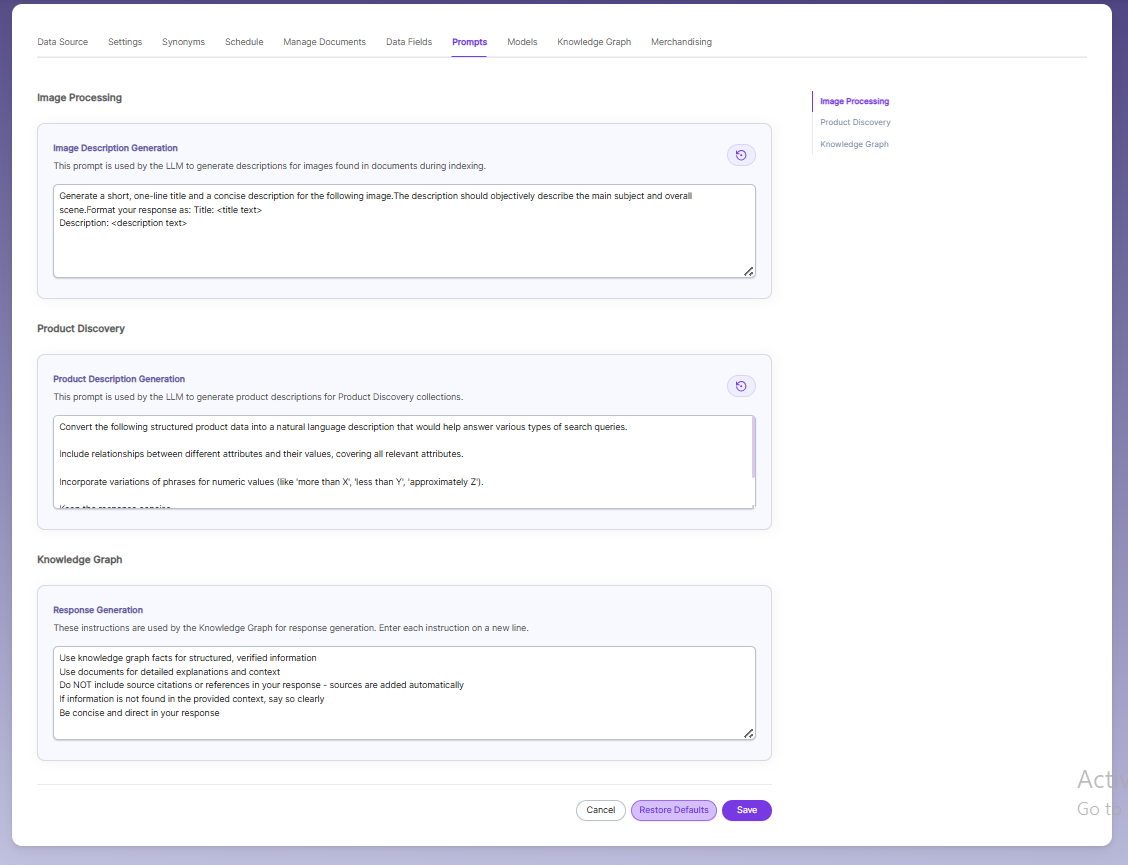
Models
The Models section lets you override the global embedding, reranking, and LLM settings for this specific collection. Changes made here apply only to the current collection and do not affect other collections.
Embedding
- Provider specifies the embedding provider used to generate vector representations of documents.
- Model defines the embedding model used to convert document content into vectors for semantic search.
Reranker
- Provider specifies the reranker provider used for improving search result relevance.
- Model defines the reranker model used to re-score and reorder search results based on relevance.
LLM
-
Provider specifies the Large Language Model provider used for AI-powered features.
-
Model defines the LLM used for tasks such as document enrichment, summaries, and SmartFAQs.
-
These settings override global configurations and apply only to the current collection.
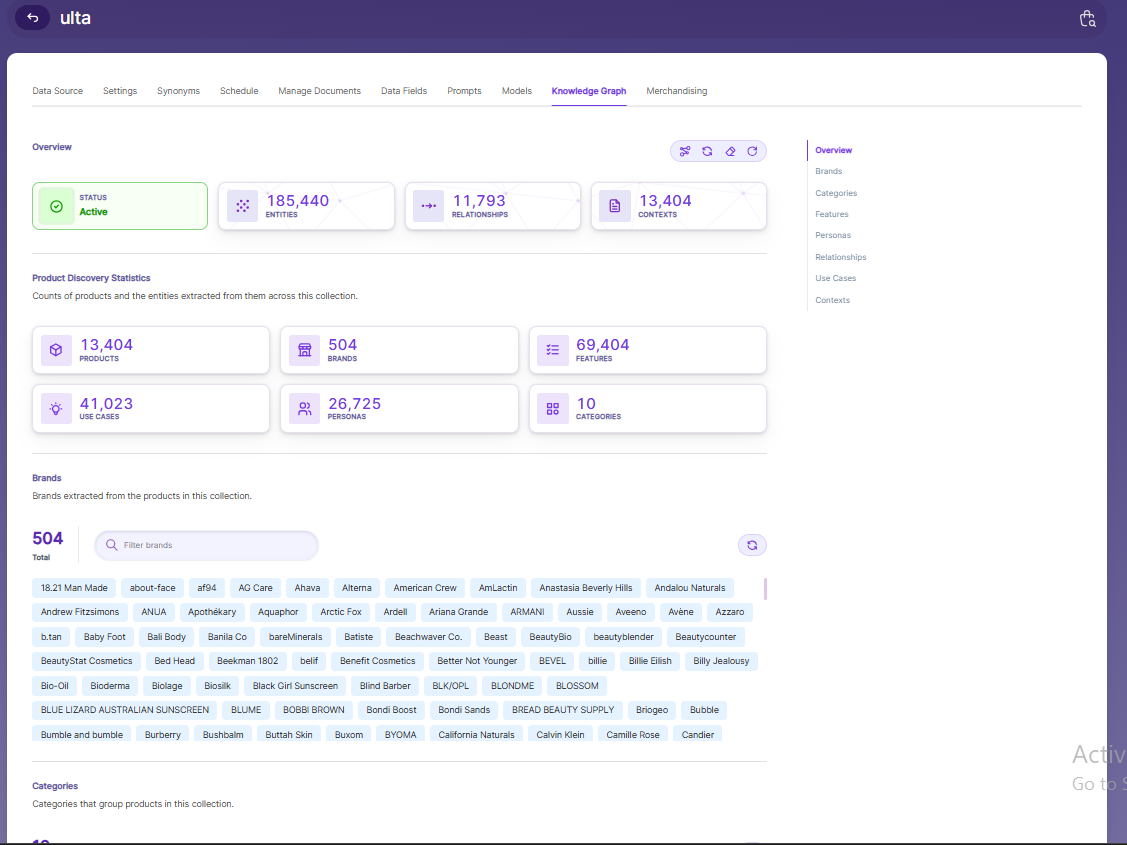
Knowledge Graph
The Knowledge Graph tab provides a structured, AI-extracted view of all entities, relationships, and contextual data derived from the products in the collection. It gives a comprehensive intelligence layer on top of raw product data to power smarter search and discovery.
Overview
The top section displays the overall Knowledge Graph status and key metrics:
| Metric | Value | Description |
|---|---|---|
| Status | Active | The Knowledge Graph is enabled and running for this collection. |
| Entities | 185,440 | Total distinct entities extracted from the product catalog. |
| Relationships | 11,793 | Connections identified between entities across the collection. |
| Contexts | 13,404 | Contextual associations linked to entities and products |
Product Discovery Statistics
Counts of products and the entities extracted from them across the collection:
| Metric | Count |
|---|---|
| Products | 13,404 |
| Brands | 504 |
| Features | 69,604 |
| Use Cases | 41,023 |
| Personas | 26,725 |
| Categories | 10 |
Brands
Displays all 504 brands automatically extracted from the product catalog, with a filter/search bar to quickly locate specific brands. Each brand appears as a tag (e.g., ARMANI, Aveeno, Burberry, Calvin Klein), enabling brand-level navigation and filtering in search.
Categories
Groups products into broader classification buckets, helping users navigate and filter the catalog by product type or segment.
Right-side Navigation Panel
Provides quick jump links to each entity type within the Knowledge Graph:
- Overview — Summary statistics
- Brands — Extracted brand entities
- Categories — Product groupings
- Features — Product attributes and characteristics
- Personas — Target user profiles associated with products
- Relationships — Connections between entities
- Use Cases — Intended applications or scenarios for products
- Contexts — Situational or environmental associations
The Knowledge Graph in a Product Discovery Collection transforms raw product data into a rich, interconnected intelligence map — enabling semantic search, faceted filtering, persona-based recommendations, and contextual product discovery far beyond simple keyword matching.
Merchandising
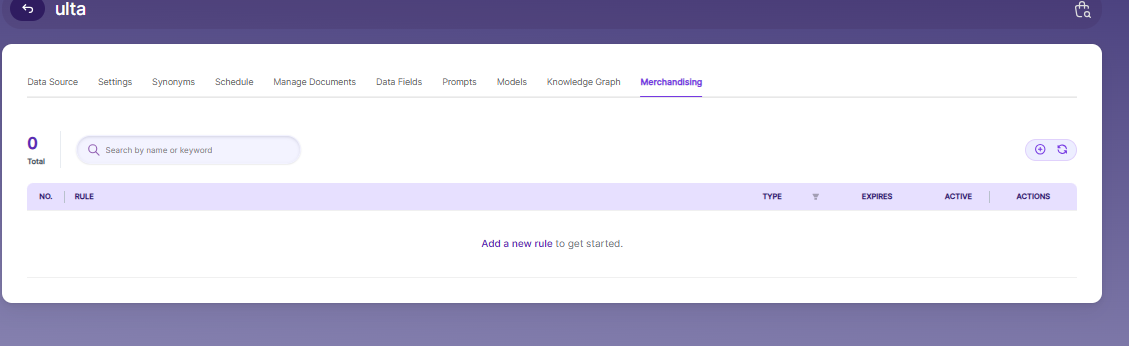
The Merchandising tab allows you to create and manage rules that control how products are presented in search results — enabling you to promote, demote, pin, or filter products based on business needs rather than purely algorithmic ranking.
The tab currently shows 0 rules configured, with a prompt to "Add a new rule to get started."
Available Controls
- Search by name or keyword — Quickly locate existing rules within large rule sets.
- Add Rule (⊕) — Creates a new merchandising rule.
- Refresh (↻) — Reloads the current rules list.
Merchandising rules give business and marketing teams direct control over search result presentation — allowing seasonal promotions, featured product placements, or suppression of out-of-stock items without requiring changes to the underlying index or search algorithm.
Note :For a detailed guide on creating and managing Merchandising rules, refer to the Merchandising documentation.
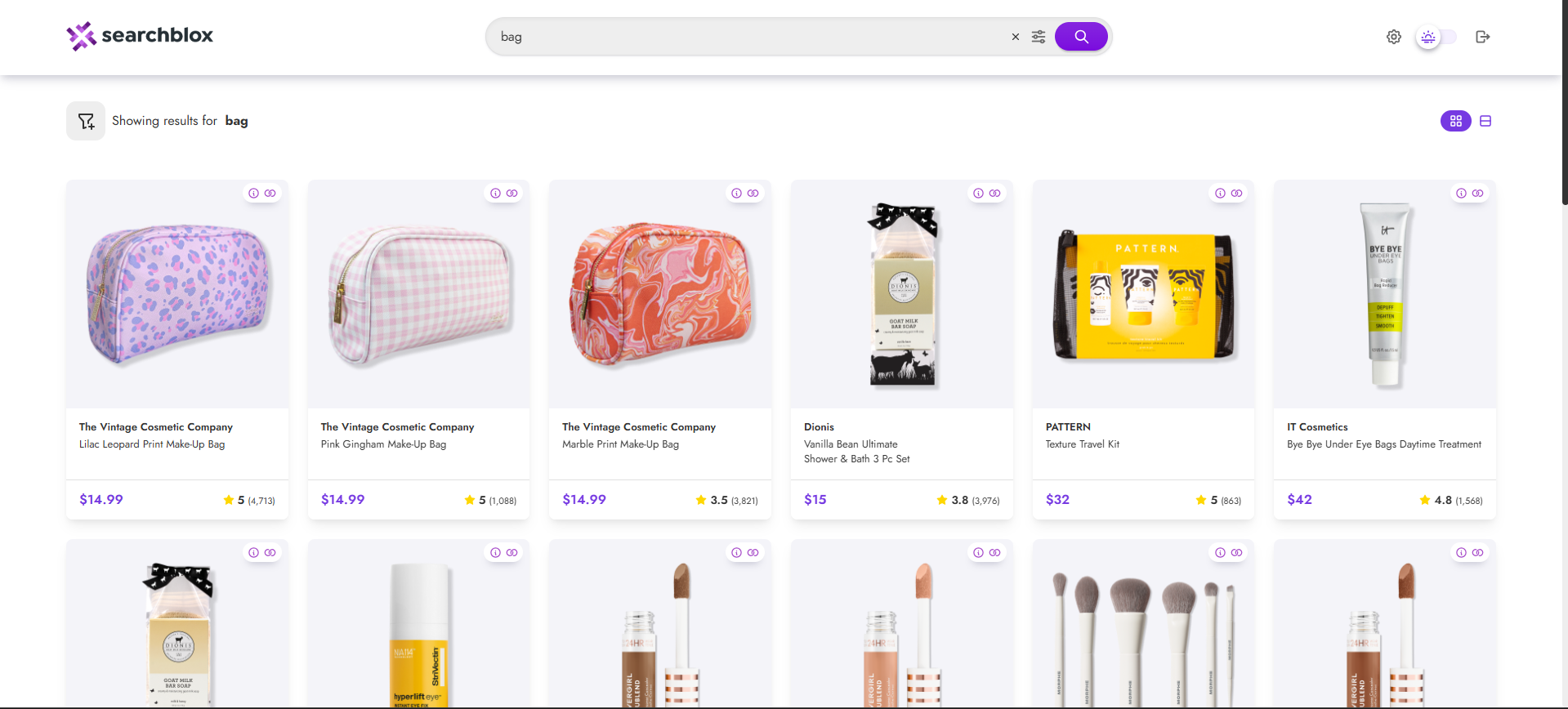
Viewing Search Results for Product Discovery Collections
-
Users can view the search results by searching for the records here: https://localhost:8443/product-discovery/index.html.
-
To know more about Product Discovery Plugin, Click here.
-
After clicking the search results, the data will appear in a grid format as shown:
Updated 22 days ago