
Email Collection
Email Collections let you index content from PST files (including attachments) and also from file systems. It’s best to use this type mainly for PST files.
Creating an Email Collection (Easy Steps)
- Log in to the Admin Console
- Go to the Collections tab
- Click "Create a New Collection" or the "+" icon
- Choose "Email Collection" as the Collection Type
- Enter a unique name (e.g., "Email Archive")
- Set Collection Access (Private or Public)
- Enable Encryption if needed
- Choose the content language
- Click Save to create the collection
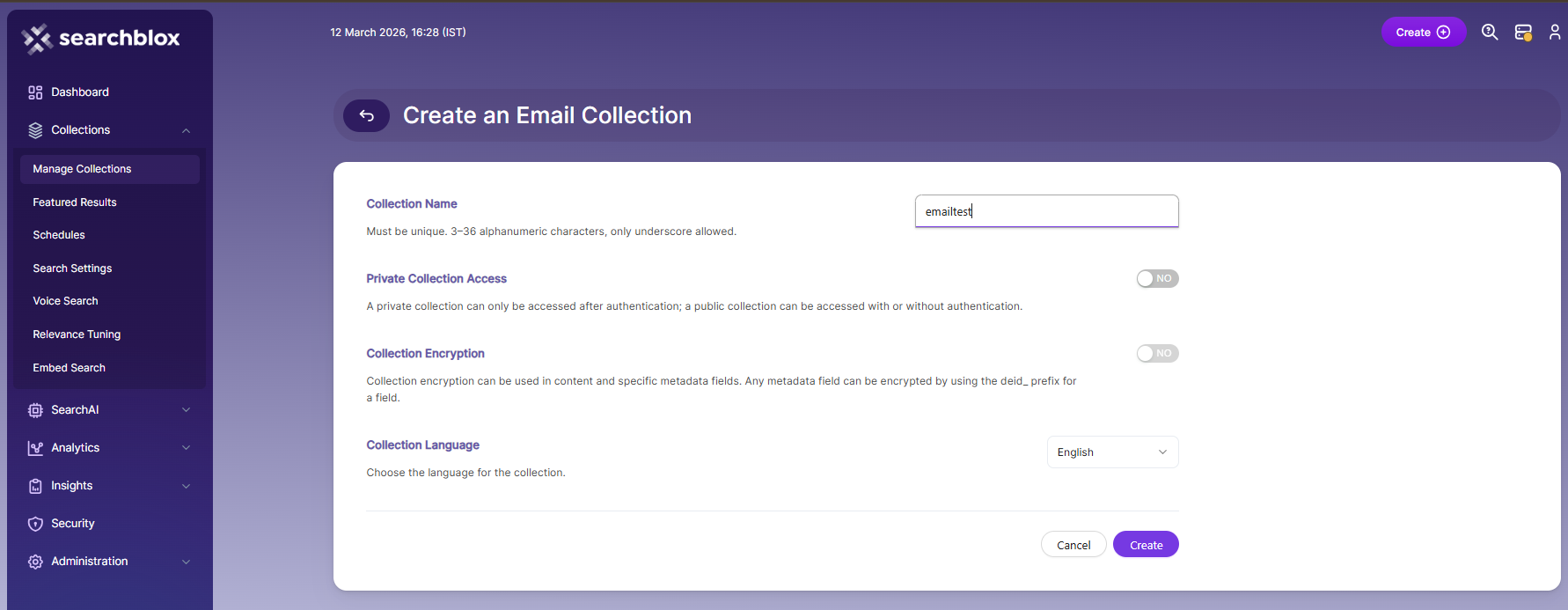
- After creating the Email Collection, you will be taken to the Path tab.
The Email Collection settings page lets you set folder paths and filters. To access these settings, click on the collection name in the Collections list.
Email Collection Path Settings
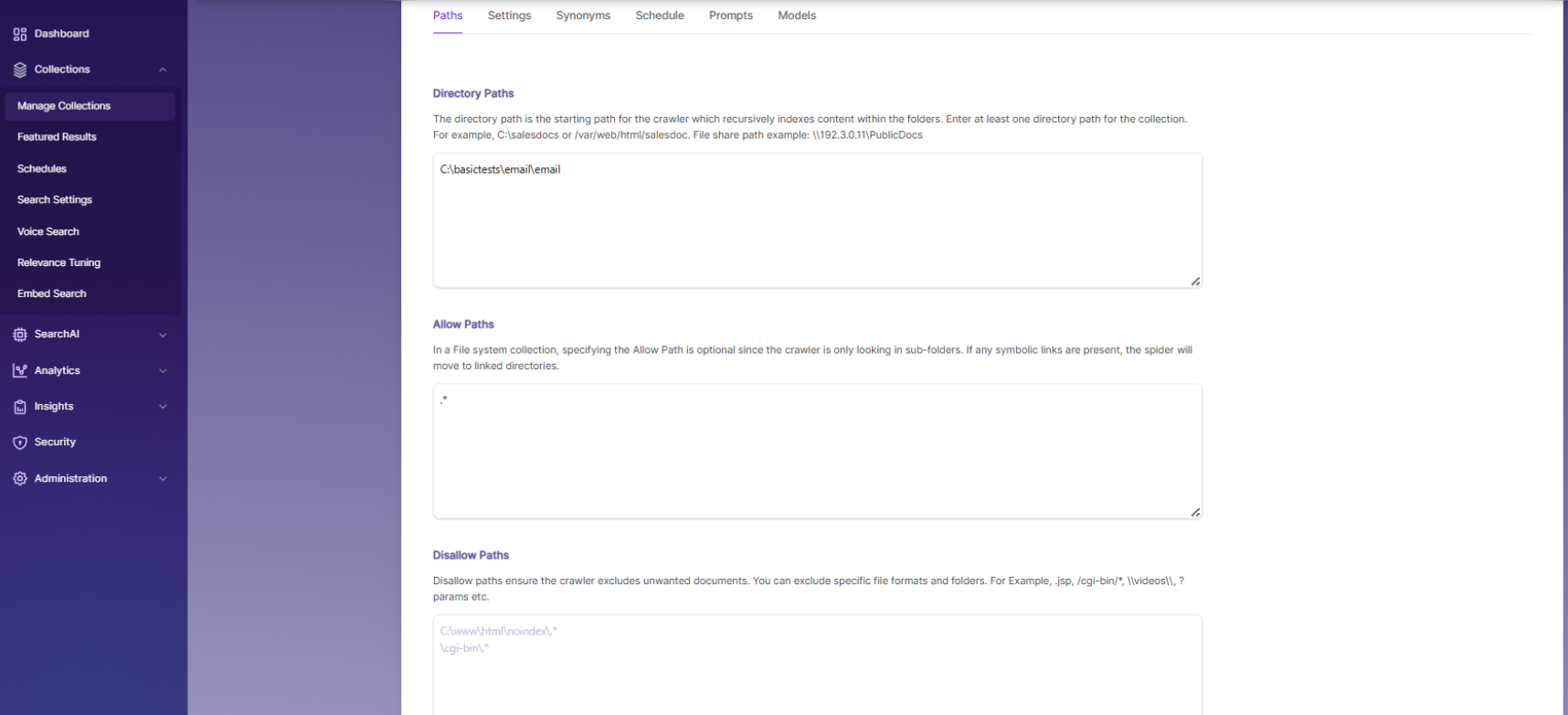
Directory Paths
The directory path is where the crawler starts indexing. It will go through all folders inside it. Enter at least one path, for example, c:\salesdocs or /var/web/html/salesdocs.
Allow/Disallow Paths
Use Allow and Disallow filters to control the collection by including only needed files and excluding unwanted ones.
| Field | Description |
|---|---|
| Directory Path | The directory path is where the crawler starts searching for files. |
| Allow Paths | C:\\www\\html\\*When creating a file system-based collection, specifying an allow filter is optional because the indexer scans all sub-folders, but if there are symbolic links, the crawler will also follow them into linked directories. |
| Disallow Paths | C:\\www\\html\\noindex\\.*\\cgi-bin\\.* |
| Allowed Formats | Select the file formats you want to include by checking the boxes. Supported formats include HTML, XML, Word, PowerPoint, Excel, Visio, PDF, Text, RTF, EPUB, AutoCAD, OpenOffice, iWorks, WordPerfect, Images, Audio, Video, PST files, Emails, and Archives. |
Email Collection Settings
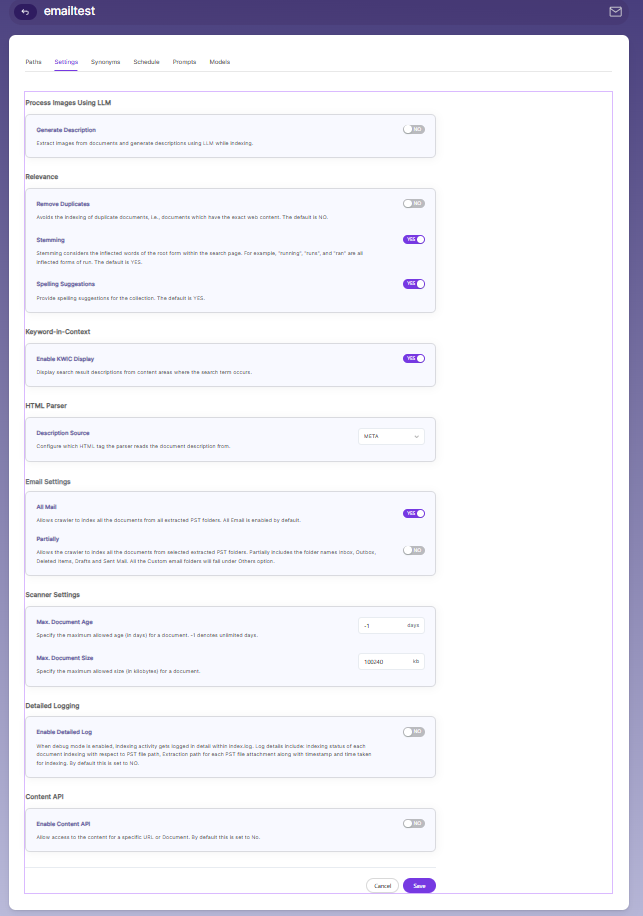
The Settings tab contains adjustable options for the Email Collection. SearchBlox provides default settings when a new collection is created.
The settings that can be configured are listed as follows:
| Setting | Description |
|---|---|
| Remove Duplicates | Turn this on to avoid indexing duplicate documents |
| Stemming | When on, words are reduced to their root form (e.g., "running", "runs", "ran" → "run"). |
| Spelling Suggestions | Provides spelling suggestions for the collection. Default setting is YES. |
| Keyword-in-Context Display | Shows search results with snippets from content where the search term appears. |
| HTML Parser Settings | Configures the HTML parser to get the document description from HTML tags like META, H1, H2, H3, H4, H5, or H6. |
| Email Settings- All Mail | Indexes all documents from all extracted PST folders. This option is enabled by default |
| Email Settings- Partially | Indexes documents only from selected PST folders. Default folders include Inbox, Outbox, Deleted Items, Drafts, and Sent Mail. Custom folders are included under “Others Option". |
| Maximum Document Age | Sets the maximum age (in days) a document can be in the collection. |
| Maximum Document Size | Sets the maximum allowed size of a document in the collection (in kilobytes). |
| Enable Detailed Log Settings | Provides detailed indexer activity in ../webapps/ROOT/logs/index.log.When logging or debug mode is enabled, the log includes: - List of files that were crawled - Processing details for each file with timestamps, whether it was indexed or skipped, recorded as separate entries - Timestamp of indexing completion and time taken for each file - Last modified date of the file - Information on skipped files and the reasons |
| Enable Content API | Allows the crawler to index content that contains special characters. |
Extraction of Emails
- Emails and attachments can be extracted to a specific folder, with all content exported to that location.
- Set the location in
<SEARCHBLOX_INSTALLATION_PATH>/webapps/searchblox/WEB-INF/pst.yml - After updating
pst.yml, restart SearchBlox, then clear and reindex the collection.

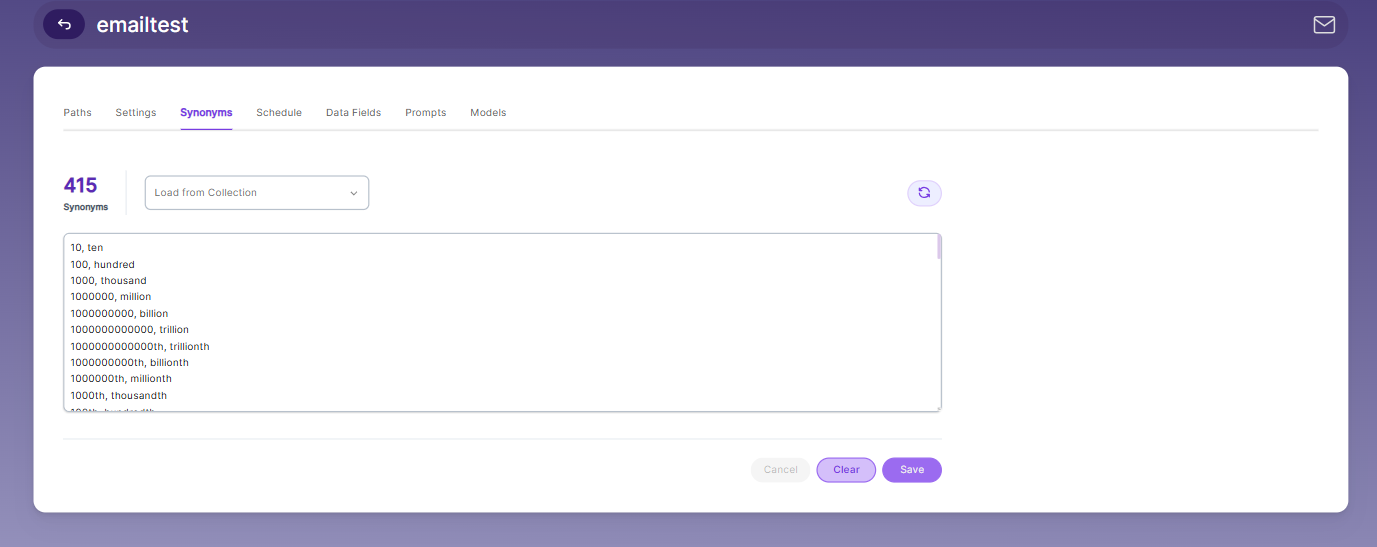
Synonyms
Synonyms help the search show relevant documents even when the exact search word is not used.
For example, if someone searches for “global,” the results can also include documents that use “world” or “international.”
We have an option to load Synonyms from the existing documents.
Schedule and Index*
Set when and how often a collection should be indexed from its root URLs. SearchBlox supports these schedule options:
-
Once
-
Hourly
-
Daily
-
Every 48 Hours
-
Every 96 Hours
-
Weekly
-
Monthly
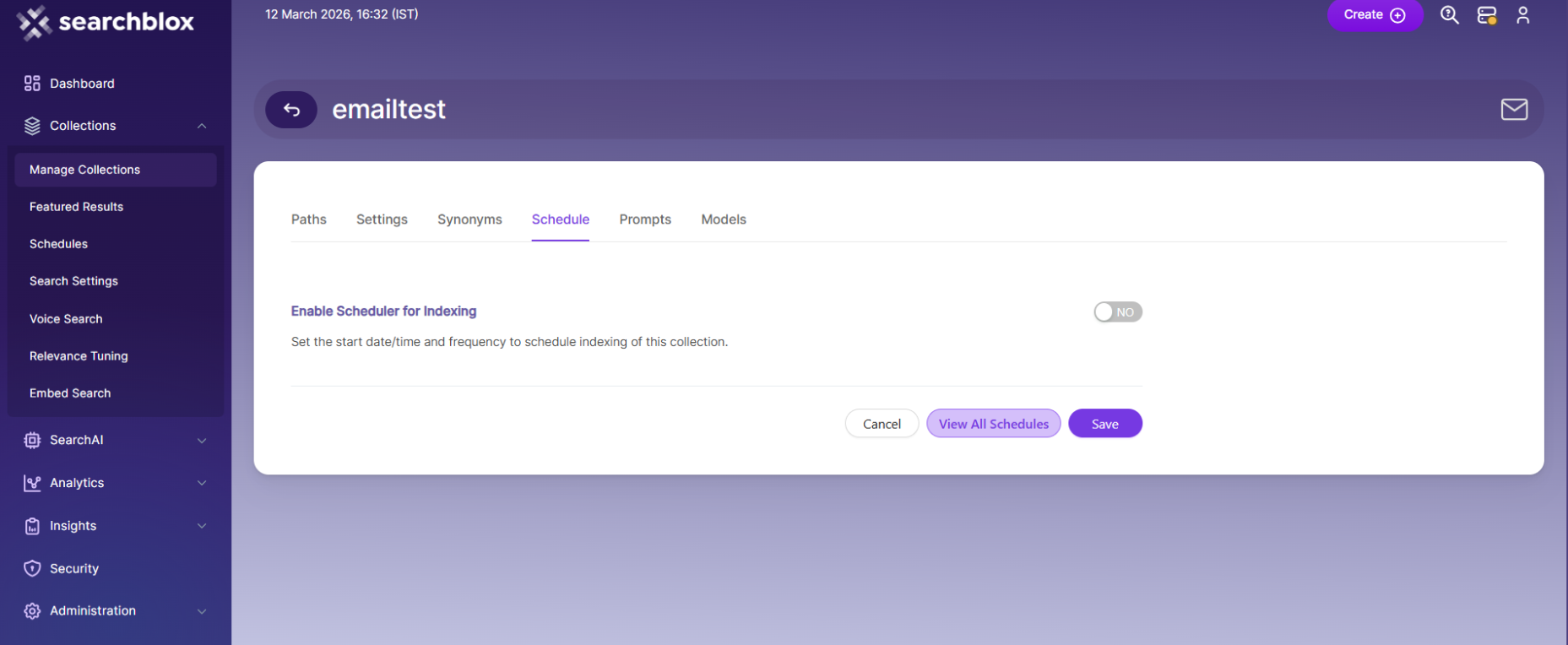
The following operations can be performed in email collections:
| Activity | Description |
|---|---|
| Enable Scheduler for Indexing | Turn this on to set the start date and how often indexing should run. |
| Save | Saves your scheduling settings for the collection. |
| View all Collection Schedules | Opens the Schedules page where you can see all scheduled collections. |
Data Fields Tab
The Data Fields tab lets you create custom fields for search and view the default fields in non-encrypted collections.
SearchBlox supports 4 types of Data Fields:
| Type | Description |
|---|---|
| Keyword | For alphanumeric values like IDs, tags, or codes |
| Number | For numeric values like prices or quantities |
| Date | For date values to use in search and filters |
| Text | For full-text search in custom fields |
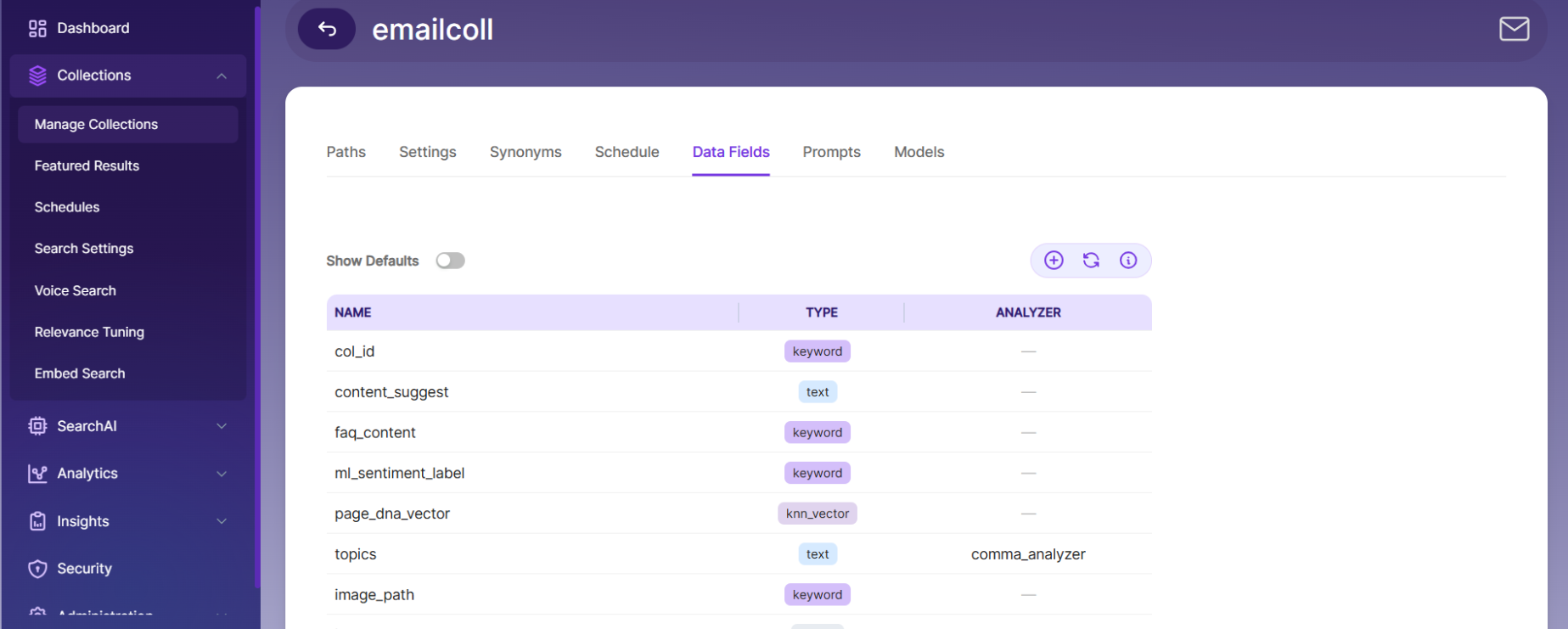
- After configuring Data Fields, you must clear and re-index the collection for changes to take effect.
To know more about Data Fields please refer to Data Fields Tab
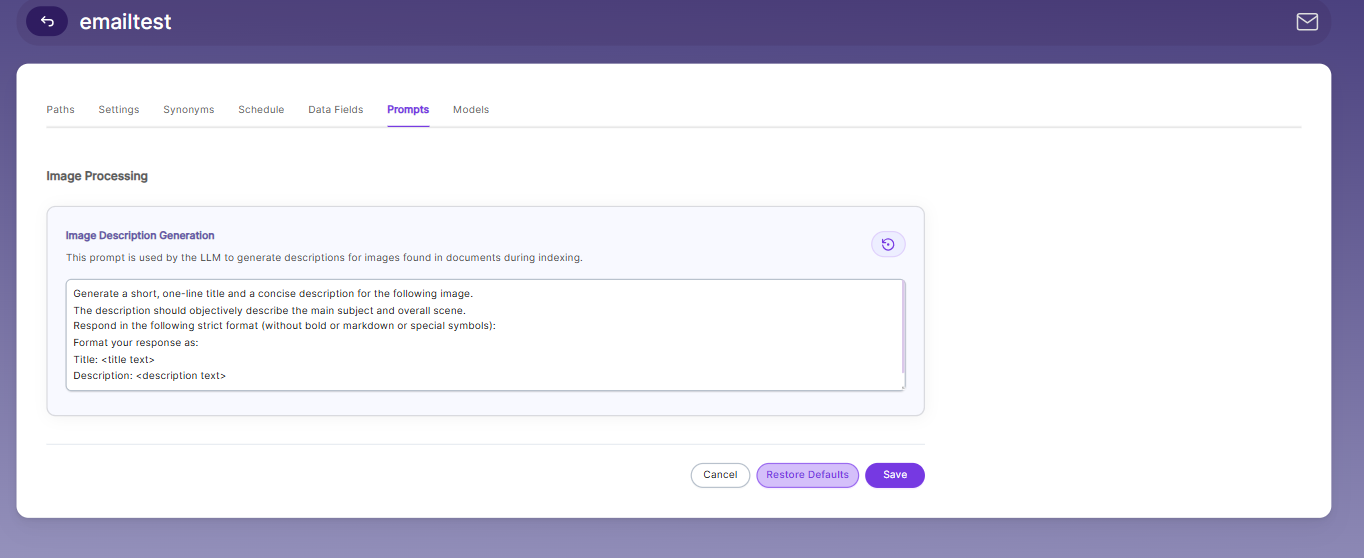
Prompts
When LLM/RAG is enabled, you can edit AI-based prompts for Title, Description, Topic, Image Description, and Smart FAQs.
You can customize these prompts anytime, and use Restore Default to reset them back to the original SearchBlox settings.
Models
The Models section lets you override the global embedding, reranking, and LLM settings for this specific collection. Changes made here apply only to the current collection and do not affect other collections.
Embedding
- Provider specifies the embedding provider used to generate vector representations of documents.
- Model defines the embedding model used to convert document content into vectors for semantic search.
Reranker
- Provider specifies the reranker provider used for improving search result relevance.
- Model defines the reranker model used to re-score and reorder search results based on relevance.
LLM
-
Provider specifies the Large Language Model provider used for AI-powered features.
-
Model defines the LLM used for tasks such as document enrichment, summaries, and SmartFAQs.
-
These settings override global configurations and apply only to the current collection.
Best Practices
- To use the email extraction and download feature, update pst.yml as mentioned earlier, restart SearchBlox, and then index the collection.
- For multiple collections, schedule them so that only 2–3 collections index or refresh at the same time.
Updated 21 days ago