
Dynamic Auto Collection
SearchBlox provides a web crawler that can index content from any intranet, portal, or website. It can also index HTTPS content without extra setup and supports crawling through a proxy server or Form Authentication.
The Dynamic Auto Collection supports Single Page Applications (SPAs) and pages that load content dynamically using JavaScript, allowing full authentication and rendering before indexing. It also supports Single Page Applications (SPAs) and pages that load content dynamically using JavaScript.
For LINUX:
Please make sure to run the following command to install the browser dependencies, which is required for
Dynamic Auto Collectionwithout form URL:
sudo apt-get install libxkbcommon0 libgbm1
Creating a Dynamic Auto Collection
To create a Dynamic Auto Collection, follow these steps:
-
Log in to the Admin Console
-
Go to the Collections tab and click Create a New Collection or the + icon
-
Choose Dynamic Auto Collection as the Collection Type
-
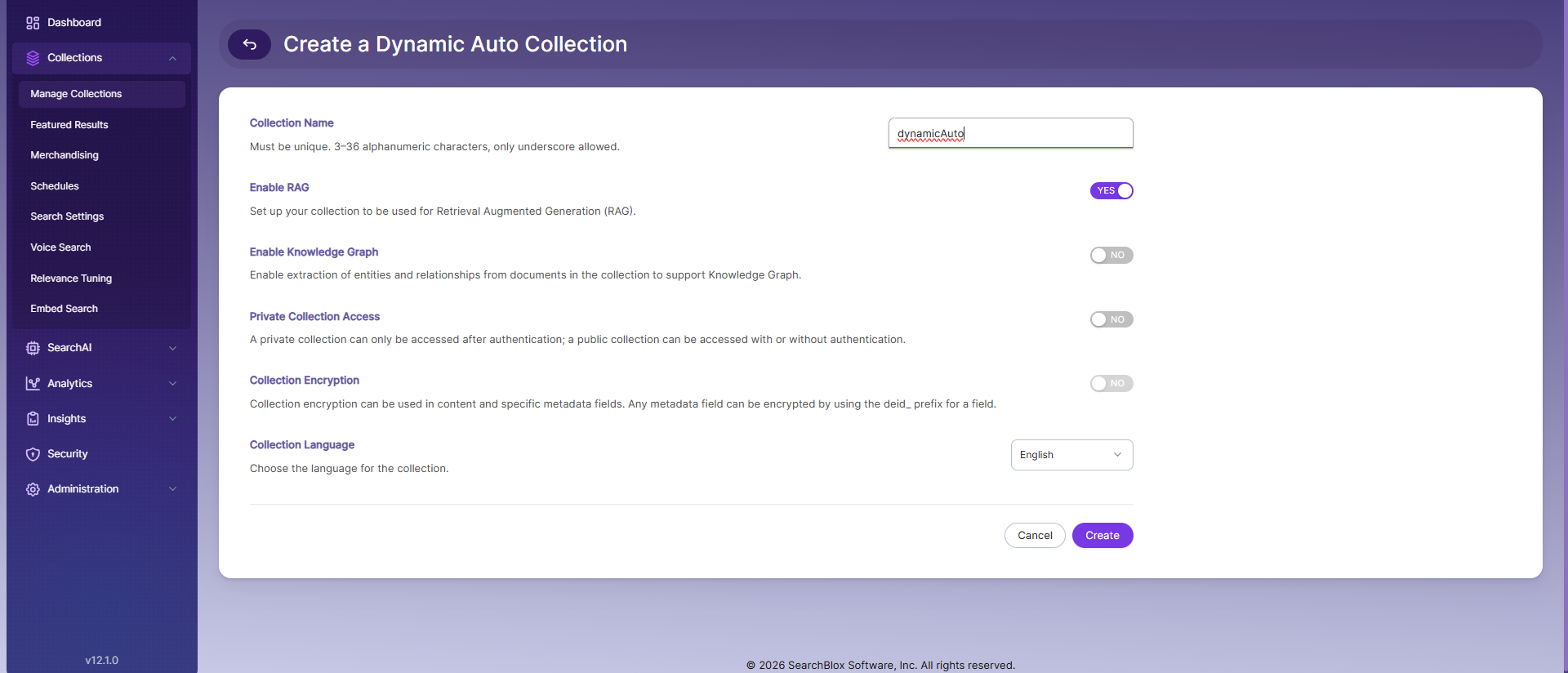
Enter a unique name for your collection (for example: "DynamicAuto")
-
Set RAG options:
- Enable if you want to use Hybrid RAG search
- Disable if you don’t need RAG features
-
Configure access settings:
- Select Private or Public access
- Turn on encryption if needed for extra security
-
Choose the content language (if it’s not English)
-
Click Save to create the collection
-
Once the Dynamic Auto Collection is created, you will be automatically redirected to the Path tab.
Dynamic Auto Collection Paths
The Dynamic Auto Collection Paths let you set the Root URLs and the Allow/Disallow paths that guide how the crawler moves through your site. These settings help you control what areas should be included or skipped during indexing. To view or update these path settings, just click on the collection name in the Collections list.
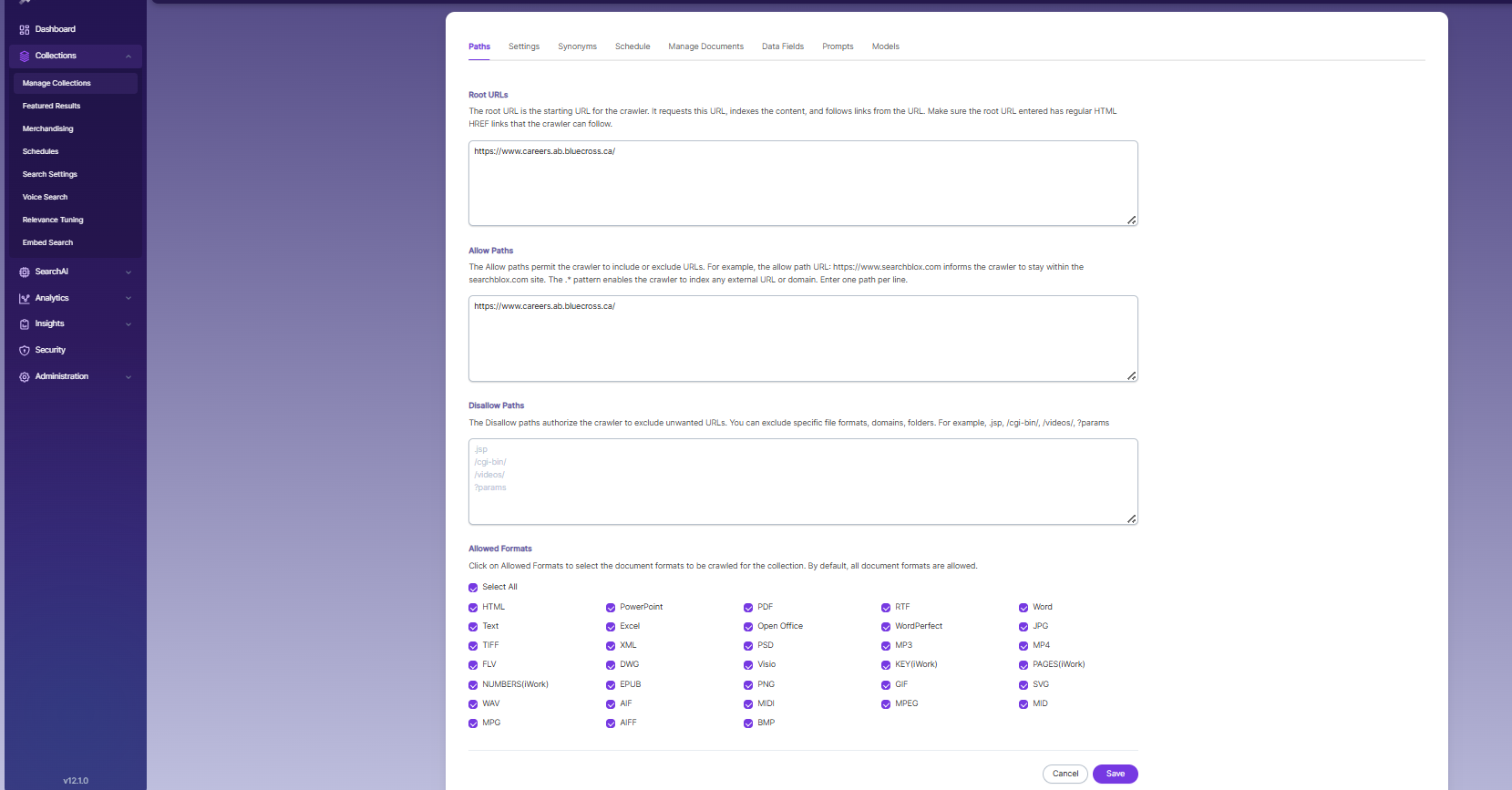
Root URLs
- The root URL is the main starting point for the crawler. It opens this URL first, indexes its content, and then follows the links found on that page.
- Only one root URL should be entered. The crawler will then move through all the pages linked from that URL.
- Make sure the root URL contains proper HTML HREF links, so the crawler can easily follow and index connected pages.
Allow/Disallow Paths
- Allow/Disallow paths help control which URLs the crawler should include or skip during indexing.
- These paths let you manage your collection by blocking unwanted URLs and allowing only the needed ones.
- In a Dynamic Auto collection, giving an allow path is required to ensure the crawler indexes only the pages within the subdomain of the root URL.
| Field | Description |
|---|---|
| Root URLs | The main starting URL for the crawler. At least one root URL is required to begin crawling. |
| Allow Paths | Tells the crawler where it can go. Example: http://www.cnn.com/ keeps crawling inside cnn.com. .* allows crawling on any external site. |
| Disallow Paths | Tells the crawler which URLs to avoid. .jsp /cgi-bin/ /videos/ ?params |
| Allowed Formats | Select which document types or file formats should be indexed and made searchable. |
Important Note:
- Enter the Root URL domain name (for example cnn.com or nytimes.com) within the Allow Paths to ensure the crawler stays within the required domains.
- If .* is left as the value within the Allow Paths, the crawler will go to any external domain and index the web pages.
Dynamic Auto Collection Settings
The Dynamic Auto Collection Settings page allows you to configure how the SearchBlox crawler behaves. When a new collection is created, default settings are automatically applied, but you can modify them anytime based on your needs. These settings help you control what the crawler collects, how deep it crawls, and how it processes different types of content, giving you full flexibility in managing the indexing process.
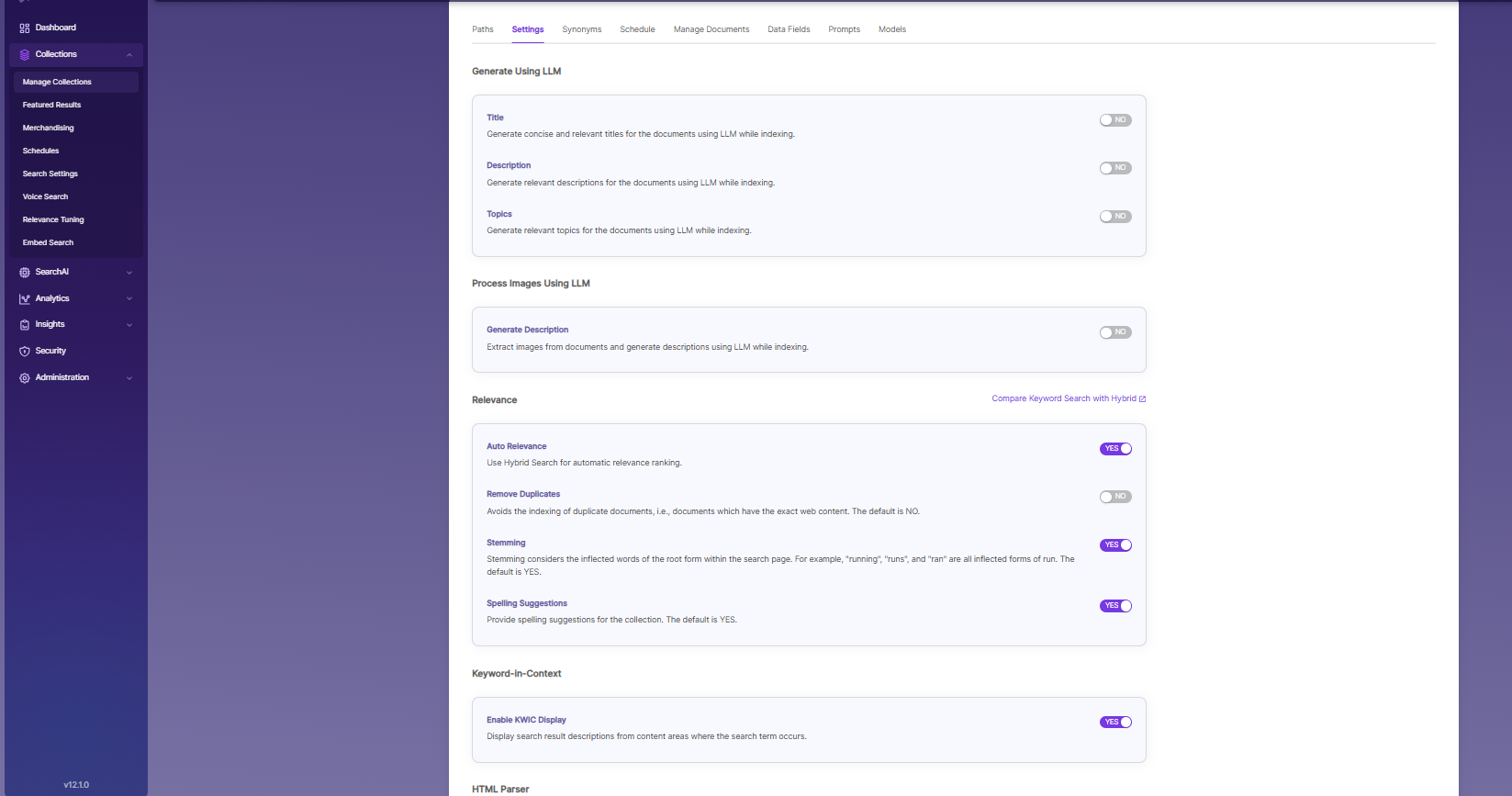
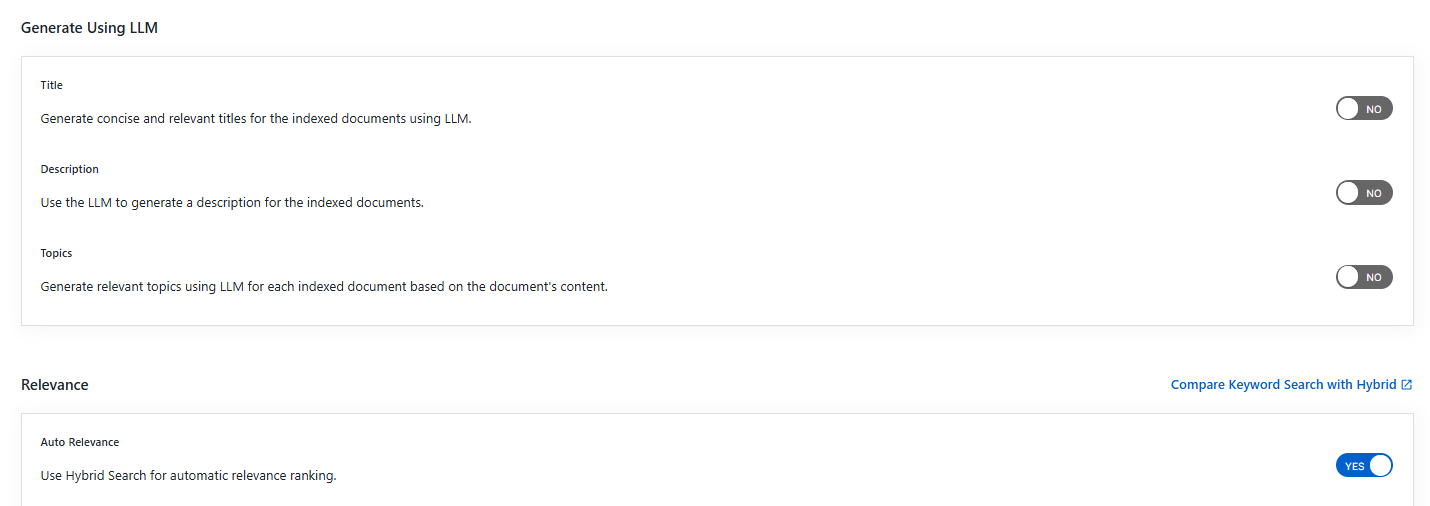
Generate Title, Description and Topics using SearchAI PrivateLLM and Enable Hybrid Search:
- Choose and enable
Generate Using LLMandAuto Relevance
- By clicking
Compare Keyword Search with Hybridlink, will redirect to the Comparison Plugin
Settings Description Title Generates concise and relevant titles for the indexed documents using LLM. Description Generates the description for indexed documents using LLM. Topic Generates relevant topics for indexed documents using LLM based on document's content. Auto Relevance Enable/Disable Hybrid Search for automatic relevance ranking
| Section | Setting | Description |
|---|---|---|
| Relevance | Auto Relevance | Turns Hybrid Search enable or disable to automatically rank search results based on relevance. |
| Relevance | Remove Duplicates | When turned enable, the system avoids indexing documents that have the same content. |
| Relevance | Stemming | Reduces words to their base form. Example: “run,” “running,” “ran,” and “runs” are treated as the same word. |
| Relevance | Spelling Suggestions | Shows spelling corrections based on indexed words. When enabled, users get suggestions in both normal and faceted search. |
| Keyword-in-Context Search Settings | Keyword-in-Context Display | The keyword-in-context feature shows search results along with a snippet of text from the page where the search term appears.. |
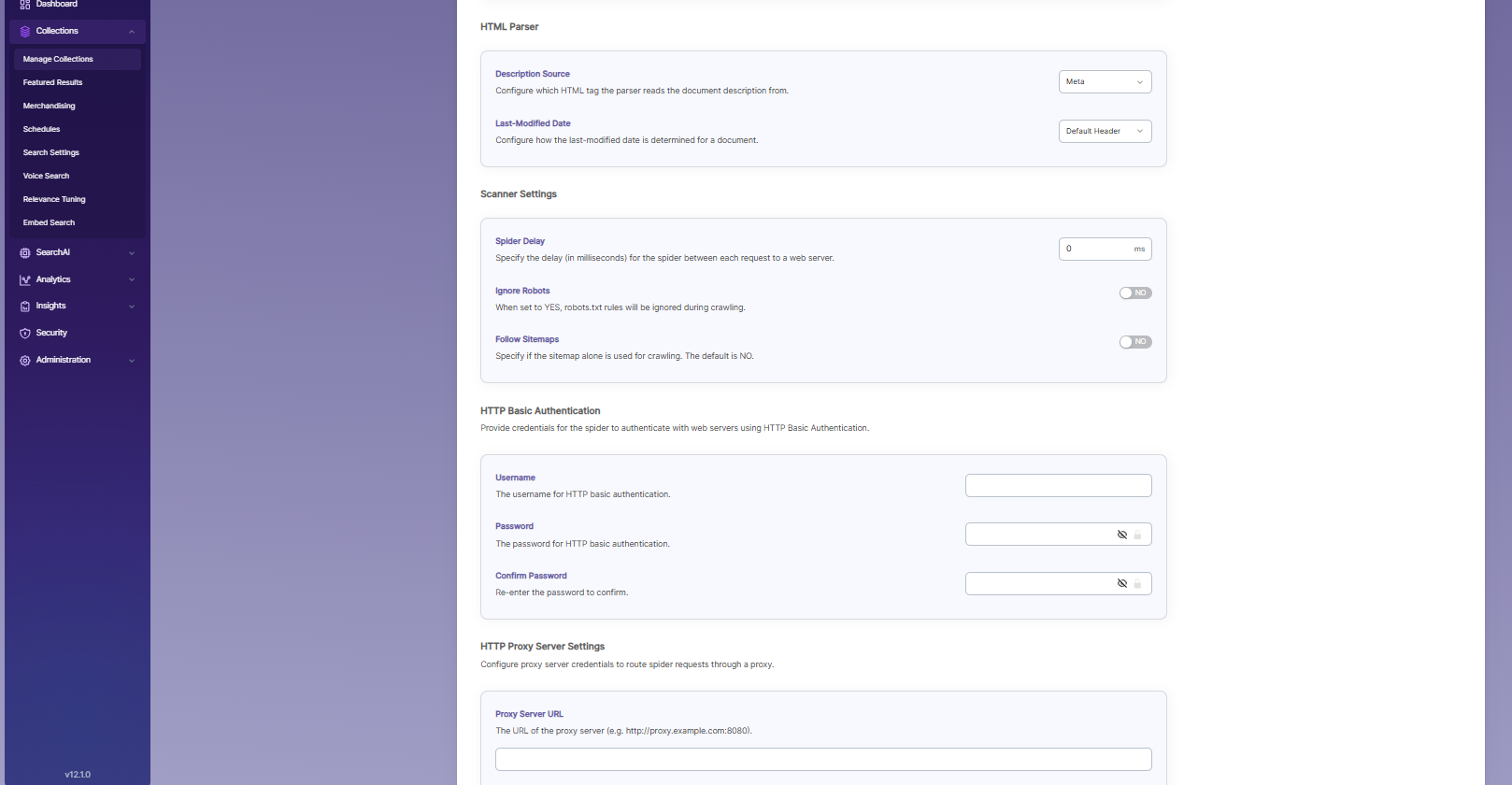
| HTML Parser Settings | Last-Modified Date | - This setting decides where the last modified date of a document is taken from. - By default, it uses the webpage header. - To use a Meta tag, select the Meta option. - To use a custom date set on the webserver, select the Custom option. |
| Scanner Settings | Spider Delay | - This setting defines how long the crawler waits (in milliseconds) between HTTP request to a web server. |
| Scanner Settings | Ignore Robots | Choose Yes or No to tell the crawler whether to follow robots.txt rules. Default is No (follows robots.txt). |
| Scanner Settings | Follow Sitemaps | Choose Yes or No to tell the crawler whether to index only sitemap URLs or all URLs on the site. Default is No. |
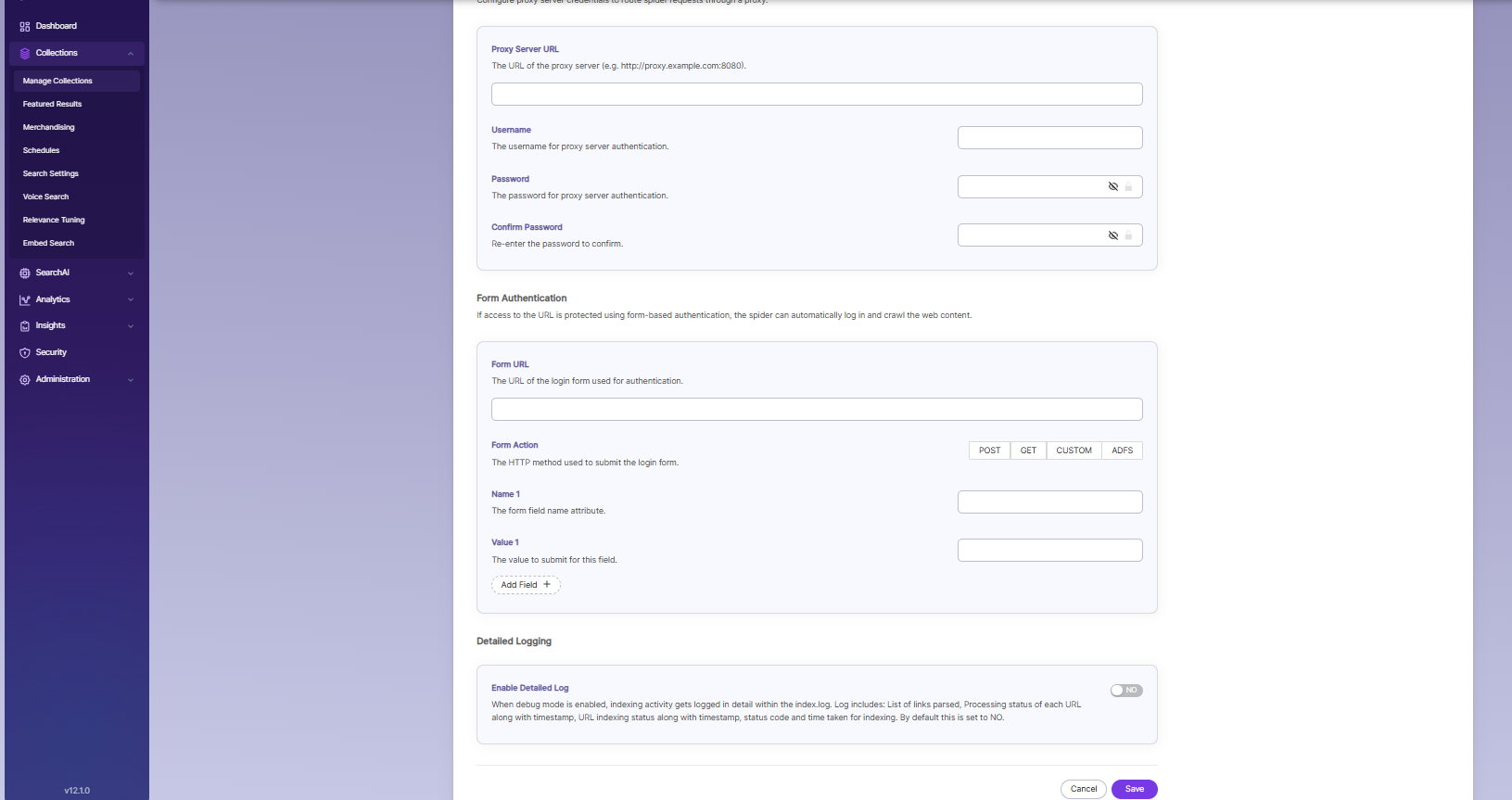
| Form Authentication | Form authentication fields | When documents are protected with form-based authentication, the crawler can automatically log in and access the content. The required attributes for form authentication are: - Form URL: The root or landing page URL after login. The crawler starts crawling from this page. - Username reference: ID or XPATH of the username field (found using Inspect Element). - Username: Enter your username. - Password reference: ID or XPATH of the password field (found using Inspect Element). - Password: Enter your password. - Submit: Type submit (do not change).- Submit reference: ID or XPATH of the submit button (found using Inspect Element). - Name 1: Optional field for actions like wait or iframe. - Value 1: Optional reference ID for wait/iframe element if required. |
| HTML Proxy server Settings | Proxy server credentials | Required when accessing HTTP content through a proxy. You need to provide the Proxy server URL, Username, and Password so the crawler can access and index the content. |
| Enable Detailed Log Settings | Enable Logging | Provides detailed indexer activity in ..\webapps\ROOT\logs\index.log. When logging or debug mode is on, it records: - List of links crawled - Processing details for each URL with timestamps, whether it was indexed or skipped - Indexing completion time and duration per URL - Last modified date of the URL - If a URL was skipped and the reason. |
Important for Linux users !
- Before indexing the created collection, navigate to
/opt/searchblox/webapps/ROOT/WEB-INF/authconfig.ymland change theheadlessvalue totrue, as shown below:
headless: true.- Restarting SearchBlox service is required to apply the above changes.
NOTE:
To add the additional time-outs, please update the below parameter in
/webapps/ROOT/WEB-INF/authconfig.yml.
submit-delay:30, where 30 will be in seconds.Restarting SearchBlox service is required to apply the above changes.
Synonyms
Synonyms allow the search engine to find documents related to a search term, even if the exact term does not appear in the content. For example, if a user searches for “global,” the search results can also include documents containing synonyms like “world” or “international.”
Additionally, there is an option to load synonyms directly from existing documents to enhance the search results.
Schedule and Index
This setting allows you to define when a collection should be indexed and how often the indexing should occur, starting from the root URLs. You can set the specific start date and time for the indexing process. SearchBlox supports different schedule frequencies, giving you control over how regularly the collection is updated.
- Once
- Hourly
- Daily
- Every 48 Hours
- Every 96 Hours
- Weekly
- Monthly
The following operation can be performed in Dynamic Auto collections
| Activity | Description |
|---|---|
| Enable Scheduler for Indexing | Turn this on to set the start date and frequency for indexing the collection. |
| Save | Save the schedule settings so the collection will follow the defined indexing plan. |
| View all Collection Schedules | Opens the Schedules section to see all scheduled indexing tasks for collections. |
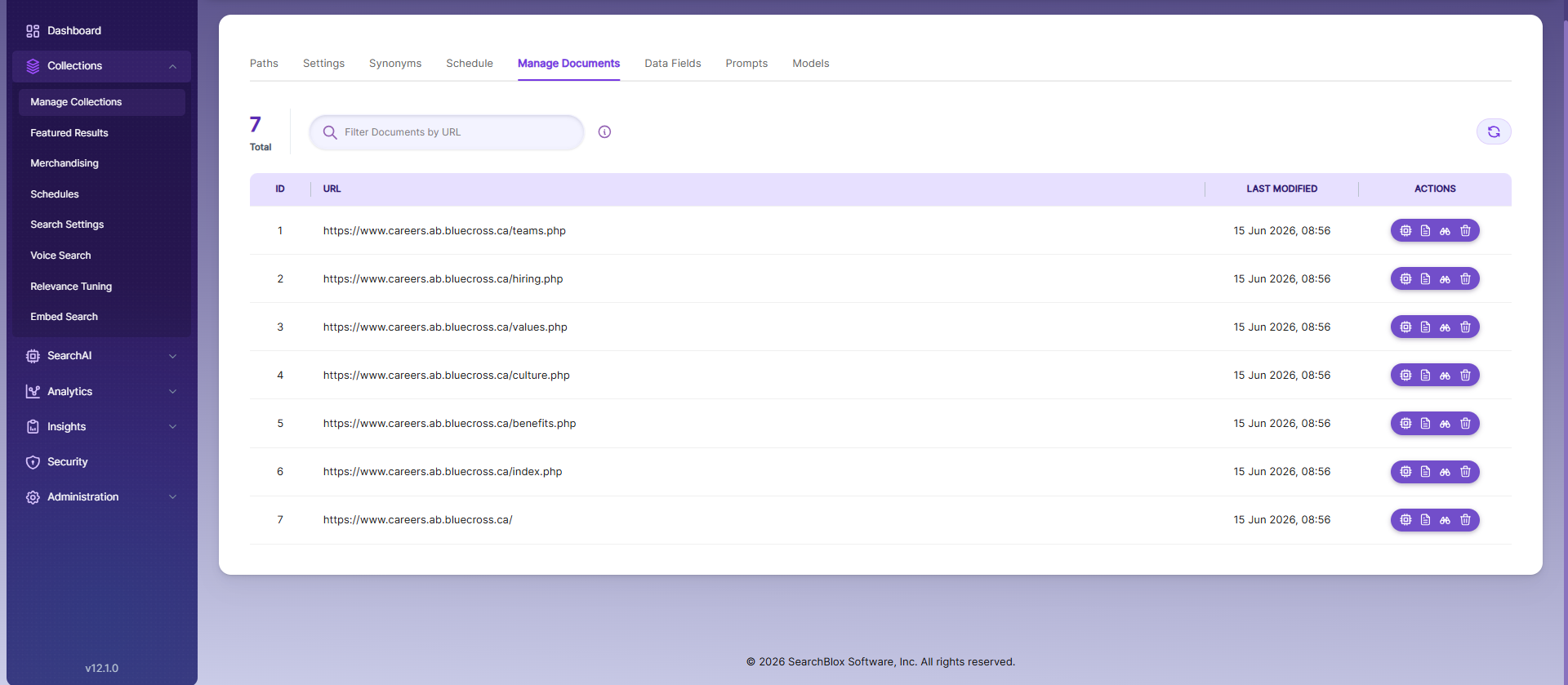
Manage Documents
-
The Manage Documents tab allows you to:
- Add/Update documents
- Filter documents
- View content
- View meta data
- Refresh documents
- Delete documents
-
To add a document, click the “+” icon.
-
Enter the document or URL, then click Add/Update.
-
After updating, the document URL will appear on the screen, and you can perform all the above operations.
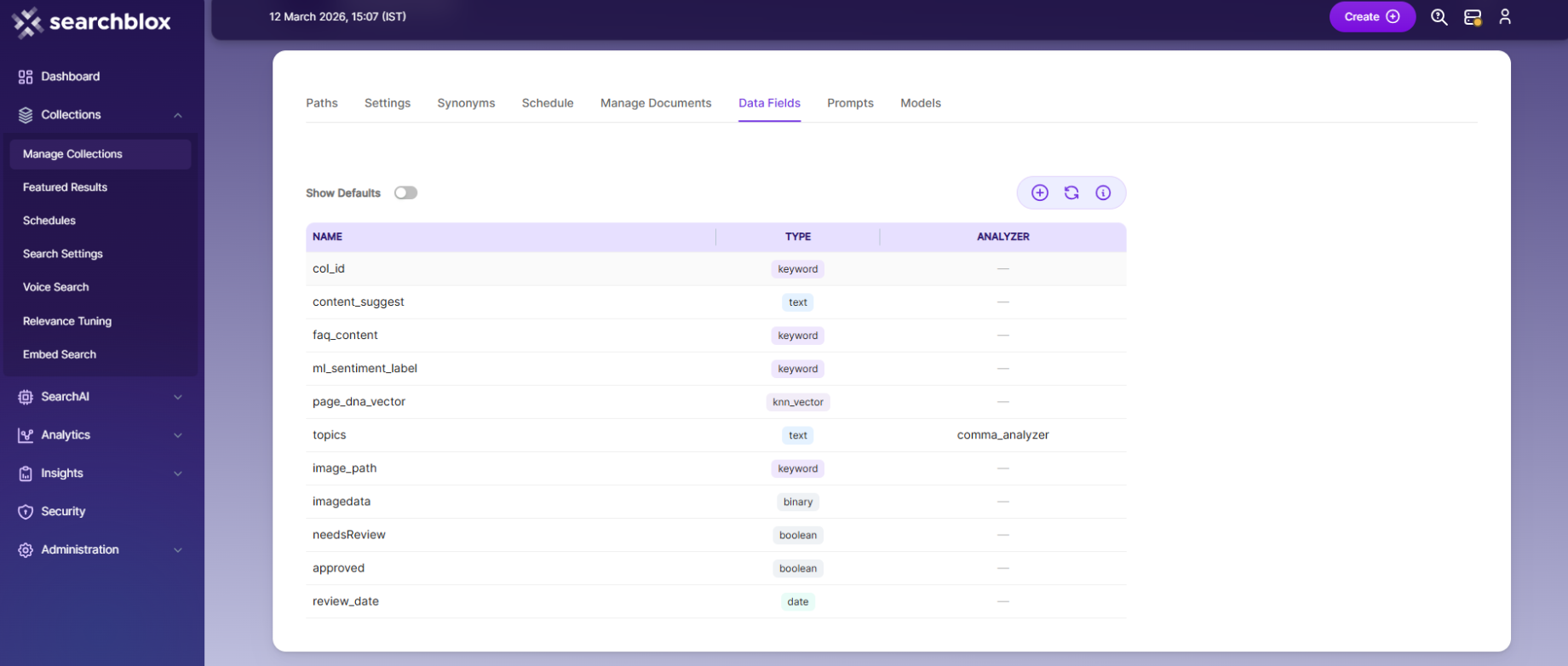
Data Fields
-
The Data Fields tab lets you create custom fields for searching. You can also see the default data fields for non-encrypted collections.
-
SearchBlox supports 4 types of data fields:**
-
Keyword – for alphanumeric values like IDs, tags, or codes.
-
Number – for numeric values like prices or quantities.
-
Date – for date values to use in search and filters.
-
Text – for full-text search in custom fields.
-
Note:
Once the Data fields are configured, collection must be cleared and re-indexed to take effect.
To know more about Data Fields please refer to Data Fields Tab
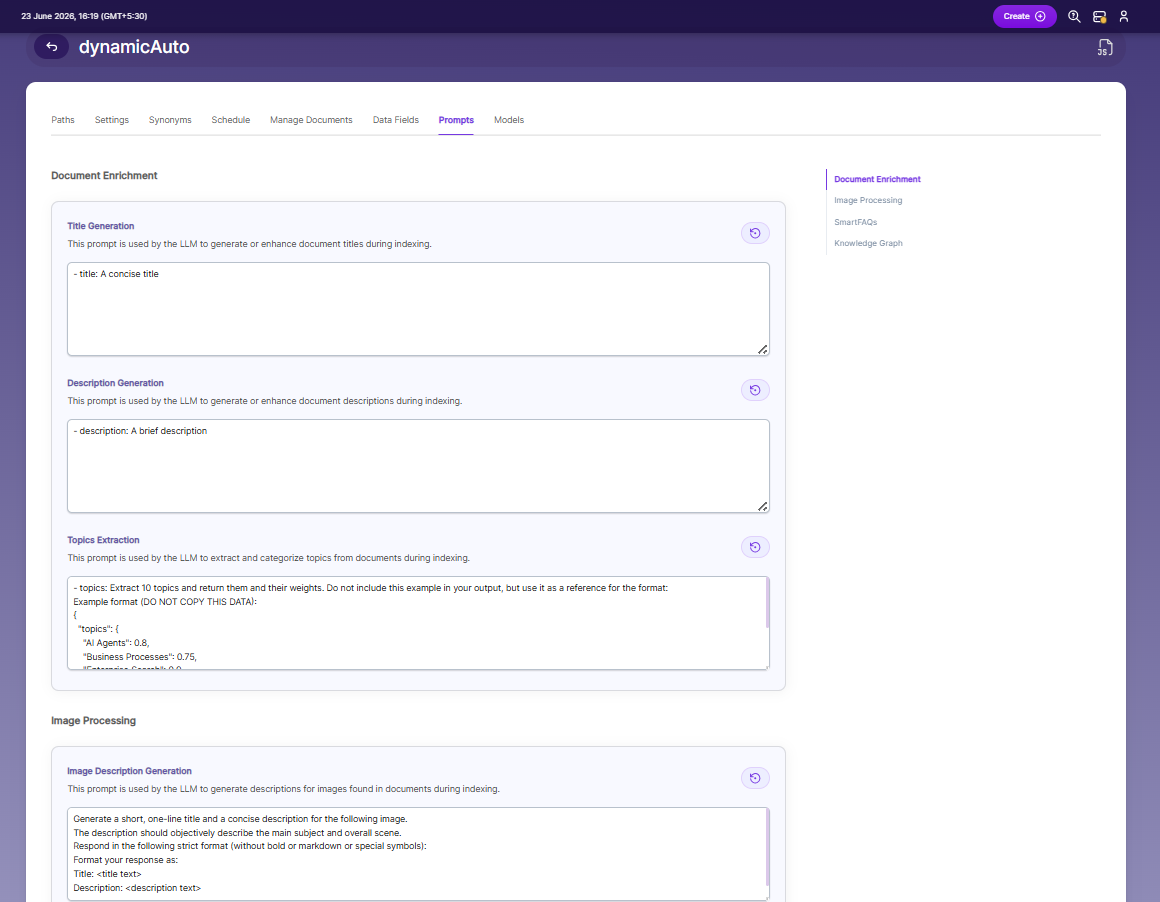
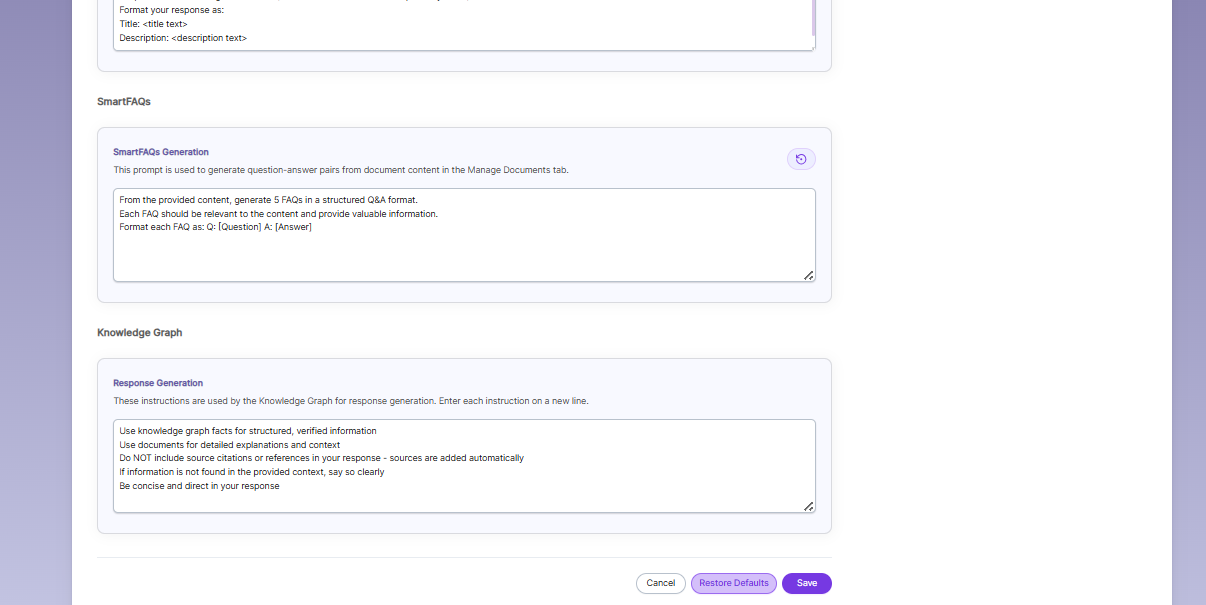
Prompts
When LLM/RAG is enabled, you can edit AI-based prompts for Title, Description, Topic, Image Description, and Smart FAQs.
You can customize these prompts anytime, and use Restore Default to reset them back to the original SearchBlox settings.
Models
The Models section lets you override the global embedding, reranking, and LLM settings for this specific collection. Changes made here apply only to the current collection and do not affect other collections.
Embedding
- Provider specifies the embedding provider used to generate vector representations of documents.
- Model defines the embedding model used to convert document content into vectors for semantic search.
Reranker
- Provider specifies the reranker provider used for improving search result relevance.
- Model defines the reranker model used to re-score and reorder search results based on relevance.
LLM
-
Provider specifies the Large Language Model provider used for AI-powered features.
-
Model defines the LLM used for tasks such as document enrichment, summaries, and SmartFAQs.
-
These settings override global configurations and apply only to the current collection.
NOTE:
If you face any trouble in indexing
Dynamic Auto Collectionand in logs if you find the following error:
ERROR <xx xxx xxxx 10:56:01,368> <status> <Exception caught on initialize browser: >
com.microsoft.playwright.PlaywrightException: Error { message='
Host system is missing dependencies to run browsers.Run the following command:
sudo apt-get install libxkbcommon0 libgbm1
Troubleshooting
Linux users: If indexing fails and you see the following error in the logs:
Exception caught on initialize browser
Host system is missing dependencies to run browsers
Run the following command and restart SearchBlox:
sudo apt-get install libxkbcommon0 libgbm1
After installation, navigate to:
/opt/searchblox/webapps/ROOT/WEB-INF/authconfig.yml
and set:
headless: true
Restart the SearchBlox service for the changes to take effect.
Note: To add additional timeouts for form authentication, update the following parameter in:
/webapps/ROOT/WEB-INF/authconfig.yml
submit-delay: 30
The value is in seconds. Restart the SearchBlox service after making this change.
Updated 12 days ago